
数据集基类(BaseDataset)
基本介绍
MMEngine 实现了一个数据集基类(BaseDataset)并定义了一些基本接口,且基于这套接口实现了一些数据集包装(DatasetWrapper)。OpenMMLab 算法库中的大部分数据集都会满足这套数据集基类定义的接口,并使用统一的数据集包装。
数据集基类的基本功能是加载数据集信息,这里我们将数据集信息分成两类,一种是元信息 (meta information),代表数据集自身相关的信息,有时需要被模型或其他外部组件获取,比如在图像分类任务中,数据集的元信息一般包含类别信息 classes,因为分类模型 model 一般需要记录数据集的类别信息;另一种为数据信息 (data information),在数据信息中,定义了具体样本的文件路径、对应标签等的信息。除此之外,数据集基类的另一个功能为不断地将数据送入数据流水线(data pipeline)中,进行数据预处理。
数据标注文件规范
OpenMMLab 2.0 数据集格式规范规定,标注文件必须为 json 或 yaml,yml 或 pickle,pkl 格式;标注文件中存储的字典必须包含 metainfo 和 data_list 两个字段。其中 metainfo 是一个字典,里面包含数据集的元信息;data_list 是一个列表,列表中每个元素是一个字典,该字典定义了一个原始数据(raw data),每个原始数据包含一个或若干个训练/测试样本。
以下是一个 JSON 标注文件的例子(该例子中每个原始数据只包含一个训练/测试样本):
{
"metainfo":
{
"classes": ["cat", "dog"]
},
"data_list":
[
{
"img_path": "xxx/xxx_0.jpg",
"img_label": 0
},
{
"img_path": "xxx/xxx_1.jpg",
"img_label": 1
}
]
}
数据集基类的初始化流程如下图所示:
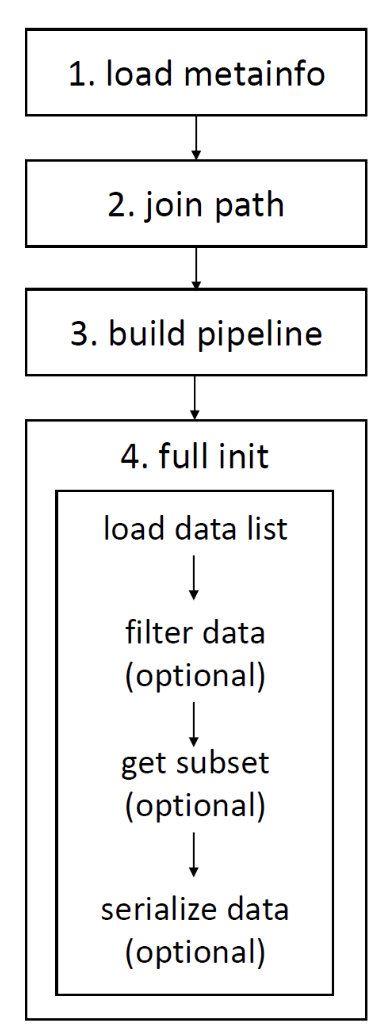
load metainfo:获取数据集的元信息,元信息有三种来源,优先级从高到低为:
-
__init__()方法中用户传入的metainfo字典;改动频率最高,因为用户可以在实例化数据集时,传入该参数; -
类属性
BaseDataset.METAINFO字典;改动频率中等,因为用户可以改动自定义数据集类中的类属性BaseDataset.METAINFO; -
标注文件中包含的
metainfo字典;改动频率最低,因为标注文件一般不做改动。如果三种来源中有相同的字段,优先级最高的来源决定该字段的值,这些字段的优先级比较是:用户传入的
metainfo字典里的字段 >BaseDataset.METAINFO字典里的字段 > 标注文件中metainfo字典里的字段。
join path:处理数据与标注文件的路径;build pipeline:构建数据流水线(data pipeline),用于数据预处理与数据准备;full init:完全初始化数据集类,该步骤主要包含以下操作:
load data list:读取与解析满足 OpenMMLab 2.0 数据集格式规范的标注文件,该步骤中会调用parse_data_info()方法,该方法负责解析标注文件里的每个原始数据;filter data(可选):根据filter_cfg过滤无用数据,比如不包含标注的样本等;默认不做过滤操作,下游子类可以按自身所需对其进行重写;get subset(可选):根据给定的索引或整数值采样数据,比如只取前 10 个样本参与训练/测试;默认不采样数据,即使用全部数据样本;serialize data(可选):序列化全部样本,以达到节省内存的效果,详情请参考节省内存;默认操作为序列化全部样本。
数据集基类中包含的 parse_data_info() 方法用于将标注文件里的一个原始数据处理成一个或若干个训练/测试样本的方法。因此对于自定义数据集类,用户需要实现 parse_data_info() 方法。
使用数据集基类自定义数据集类
对于满足 OpenMMLab 2.0 数据集格式规范的标注文件,用户可以重载 parse_data_info() 来加载标签。
import os.path as osp
from mmengine.dataset import BaseDataset
class ToyDataset(BaseDataset):
# 以上面标注文件为例,在这里 raw_data_info 代表 `data_list` 对应列表里的某个字典:
# {
# 'img_path': "xxx/xxx_0.jpg",
# 'img_label': 0,
# ...
# }
def parse_data_info(self, raw_data_info):
data_info = raw_data_info
img_prefix = self.data_prefix.get('img_path', None)
if img_prefix is not None:
data_info['img_path'] = osp.join(
img_prefix, data_info['img_path'])
return data_info