
0 参考资料:
深入浅出完整解析Stable Diffusion XL(SDXL)核心基础知识
How to run SDXL v1.0 with AUTOMATIC1111
1 Stable Diffusion XL算法原理
1.1 Stable Diffusion XL核心基础内容
Stable Diffusion XL是Stable Diffusion的优化版本。相当于:yolov8是 yolo的优化版本
与Stable DiffusionV1-v2相比,Stable Diffusion XL主要做了如下的优化:
- 对Stable Diffusion原先的U-Net,VAE,CLIP Text Encoder三大件都做了改进。
- 增加一个单独的基于Latent的Refiner模型,来提升图像的精细化程度。
- 设计了很多训练Tricks,包括图像尺寸条件化策略,图像裁剪参数条件化以及多尺度训练等。
- 先发布Stable Diffusion XL 0.9测试版本,基于用户使用体验和生成图片的情况,针对性增加数据集和使用RLHF技术优化迭代推出Stable Diffusion XL 1.0正式版。
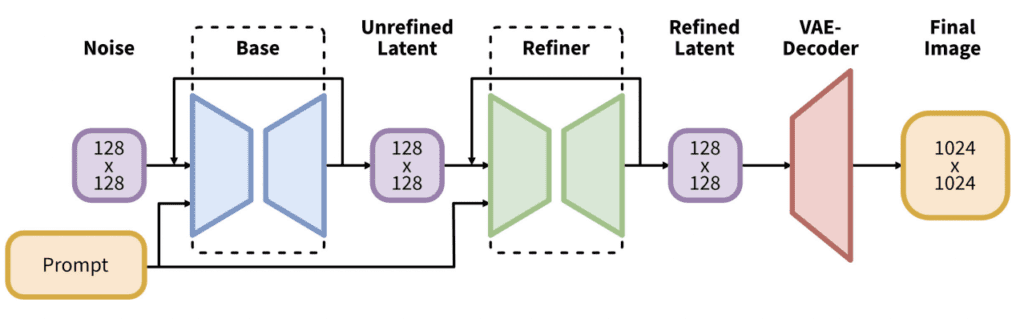
1.2 SDXL整体架构
Stable Diffusion XL是一个二阶段的级联扩散模型,包括Base模型和Refiner模型。其中Base模型的主要工作和Stable Diffusion一致,具备文生图,图生图,图像inpainting等能力。在Base模型之后,级联了Refiner模型,对Base模型生成的图像Latent特征进行精细化,其本质上是在做图生图的工作。Base模型用于生成有噪声的latent,这些latent在最后的去噪步骤中使用专门的Refiner模型进行处理。Base模型可以单独使用,但Refiner模型只能依附base模式使用提高图像的清晰度和质量。
Base模型由U-Net,VAE,CLIP Text Encoder(两个)三个模块组成,在FP16精度下Base模型大小6.94G(FP32:13.88G),其中U-Net大小5.14G,VAE模型大小167M以及两个CLIP Text Encoder一大一小分别是1.39G和246M。
Refiner模型同样由U-Net,VAE,CLIP Text Encoder(一个)三个模块组成,在FP16精度下Refiner模型大小6.08G,其中U-Net大小4.52G,VAE模型大小167M(与Base模型共用)以及CLIP Text Encoder模型大小1.39G(与Base模型共用)。
1.3 VAE模型
VAE模型(变分自编码器,Variational Auto-Encoder)是一个经典的生成式模型。在传统深度学习时代,GAN的风头完全盖过了VAE,但VAE简洁稳定的Encoder-Decoder架构,以及能够高效提取数据Latent特征的关键能力,让其跨过了周期,在AIGC时代重新繁荣。
Stable Diffusion XL依旧是基于Latent的扩散模型,所以VAE的Encoder和Decoder结构依旧是Stable Diffusion XL提取图像Latent特征和图像像素级重建的关键一招。
对于一个大小为$H×W ×3$的输入图像,encoder模块将其编码为一个大小为$h×w ×c$的latent,其中$f = H/h=W/w$为下采样率(downsampling factor)。在ImageNet数据集上训练同样的步数(2M steps),其训练过程的生成质量如下所示,可以看到过小的$f$(比如1和2)下收敛速度慢,此时图像的感知压缩率较小,扩散模型需要较长的学习;而过大的$f$其生成质量较差,此时压缩损失过大。
当$f$在4~16时,可以取得相对好的效果。SD采用基于KL-reg的autoencoder,其中下采样率$f=8$,特征维度为$c=4$,当输入图像为512x512大小时将得到64x64x4大小的latent。 autoencoder模型是在OpenImages数据集上基于256x256大小训练的,但是由于autoencoder的模型是全卷积结构的(基于ResnetBlock,只有模型的中间存在两个self attention层),所以它可以扩展应用在尺寸>256的图像上。下面我们给出使用diffusers库来加载autoencoder模型,并使用autoencoder来实现图像的压缩和重建,代码如下所示:
import torch
from diffusers import AutoencoderKL
import numpy as np
from PIL import Image
#加载模型: autoencoder可以通过SD权重指定subfolder来单独加载
autoencoder = AutoencoderKL.from_pretrained("runwayml/stable-diffusion-v1-5", subfolder="vae")
autoencoder.to("cuda", dtype=torch.float16)
# 读取图像并预处理
raw_image = Image.open("boy.png").convert("RGB").resize((256, 256))
image = np.array(raw_image).astype(np.float32) / 127.5 - 1.0
image = image[None].transpose(0, 3, 1, 2)
image = torch.from_numpy(image)
# 压缩图像为latent并重建
with torch.inference_mode():
latent = autoencoder.encode(image.to("cuda", dtype=torch.float16)).latent_dist.sample()
rec_image = autoencoder.decode(latent).sample
rec_image = (rec_image / 2 + 0.5).clamp(0, 1)
rec_image = rec_image.cpu().permute(0, 2, 3, 1).numpy()
rec_image = (rec_image * 255).round().astype("uint8")
rec_image = Image.fromarray(rec_image[0])
rec_image
这里给出了两张图片在256x256和512x512下的重建效果对比,如下所示,第一列为原始图片,第二列为512x512尺寸下的重建图,第三列为256x256尺寸下的重建图。对比可以看出,autoencoder将图片压缩到latent后再重建其实是有损的,比如会出现文字和人脸的畸变,在256x256分辨率下是比较明显的,512x512下效果会好很多。


这种有损压缩肯定是对SD的生成图像质量是有一定影响的,不过好在SD模型基本上是在512x512以上分辨率下使用的。为了改善这种畸变,stabilityai在发布SD 2.0时同时发布了两个在LAION子数据集上精调的autoencoder,注意这里只精调autoencoder的decoder部分,SD的UNet在训练过程只需要encoder部分,所以这样精调后的autoencoder可以直接用在先前训练好的UNet上(这种技巧还是比较通用的,比如谷歌的Parti也是在训练好后自回归生成模型后,扩大并精调ViT-VQGAN的decoder模块来提升生成质量)。
在损失函数方面,使用了久经考验的生成领域“交叉熵”—感知损失(perceptual loss)以及回归损失来约束VAE的训练过程。
同时由于SD采用的autoencoder是基于KL-reg的,所以这个autoencoder在编码图像时其实得到的是一个高斯分布DiagonalGaussianDistribution(分布的均值和标准差),然后通过调用sample方法来采样一个具体的latent(调用mode方法可以得到均值)。由于KL-reg的权重系数非常小,实际得到latent的标准差还是比较大的,latent diffusion论文中提出了一种rescaling方法:首先计算出第一个batch数据中的latent的标准差$\hat{\sigma}$,然后采用$1/\hat{\sigma}$的系数来rescale latent,这样就尽量保证latent的标准差接近1(防止扩散过程的SNR较高,影响生成效果,具体见latent diffusion论文的D1部分讨论),然后扩散模型也是应用在rescaling的latent上,在解码时只需要将生成的latent除以$1/\hat{\sigma}$,然后再送入autoencoder的decoder即可。对于SD所使用的autoencoder,这个rescaling系数为0.18215。
当输入是图片时,Stable Diffusion XL和Stable Diffusion一样,首先会使用VAE的Encoder结构将输入图像转换为Latent特征,然后U-Net不断对Latent特征进行优化,最后使用VAE的Decoder结构将Latent特征重建出像素级图像。除了提取Latent特征和图像的像素级重建外,VAE还可以改进生成图像中的高频细节,小物体特征和整体图像色彩。
当Stable Diffusion XL的输入是文字时,这时我们不需要VAE的Encoder结构,只需要Decoder进行图像重建。VAE的灵活运用,让Stable Diffusion系列增添了几分优雅。
Stable Diffusion XL使用了和之前Stable Diffusion系列一样的VAE结构,但在训练中选择了更大的Batch-Size(256 vs 9),并且对模型进行指数滑动平均操作(EMA,exponential moving average),EMA对模型的参数做平均,从而提高性能并增加模型鲁棒性。
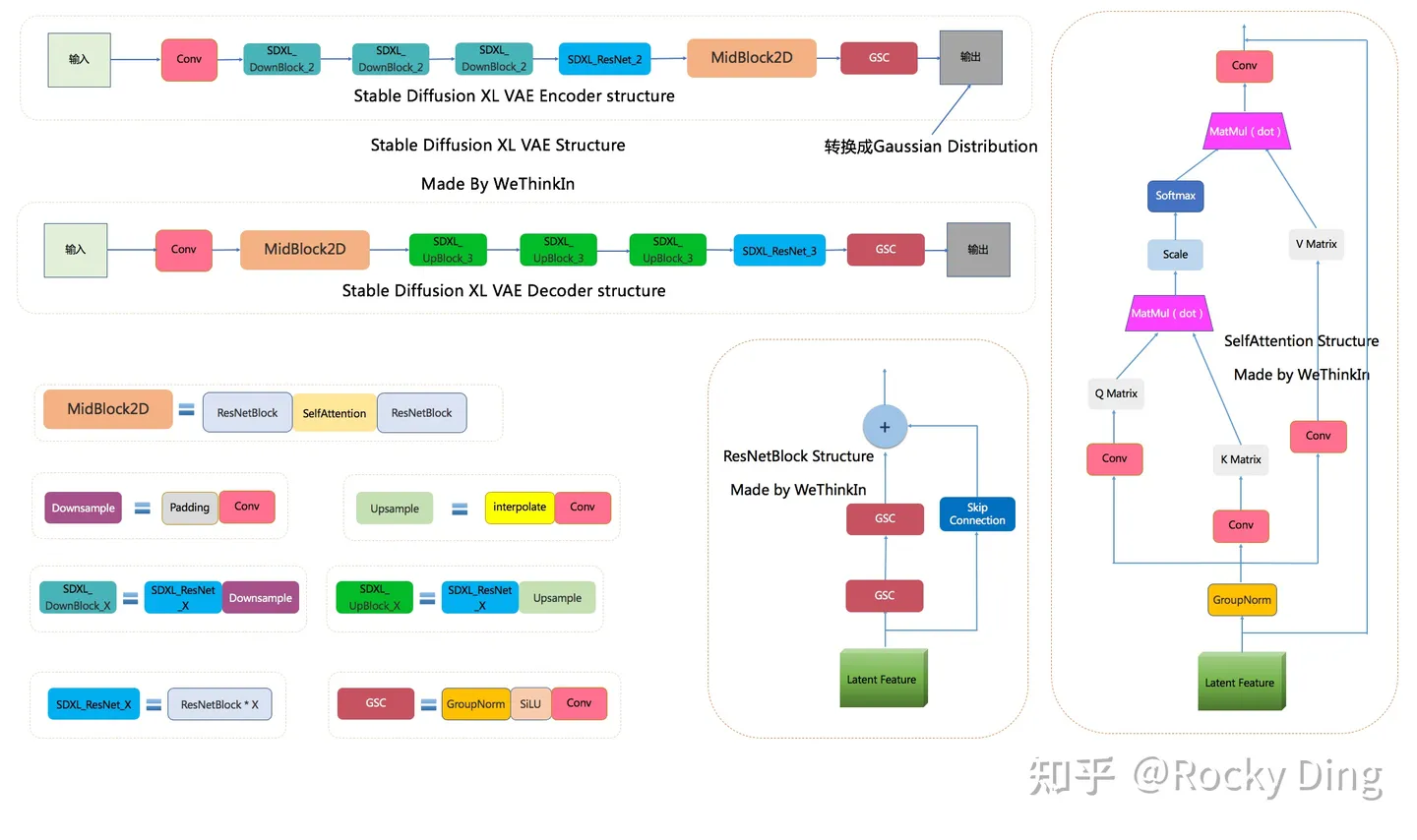
与此同时,VAE的缩放系数也产生了变化。VAE在将Latent特征送入U-Net之前,需要对Latent特征进行缩放让其标准差尽量为1,之前的Stable Diffusion系列采用的缩放系数为0.18215,由于Stable Diffusion XL的VAE进行了全面的重训练,所以缩放系数重新设置为0.13025。
注意:由于缩放系数的改变,Stable Diffusion XL VAE模型与之前的Stable Diffusion系列并不兼容。
1.4 CLIP Text Encoder模型
CLIP模型主要包含Text Encoder和Image Encoder两个模块,在Stable Diffusion XL中,和之前的Stable Diffusion系列一样,只使用Text Encoder模块从文本信息中提取Text Embeddings。
不过Stable Diffusion XL与之前的系列相比,使用了两个CLIP Text Encoder,分别是OpenCLIP ViT-bigG(1.39G)和OpenAI CLIP ViT-L(246M),从而大大增强了Stable Diffusion XL对文本的提取和理解能力。
其中OpenCLIP ViT-bigG是一个只由Transformer模块组成的模型,一共有32个CLIPEncoder模块,是一个强力的特征提取模型。
OpenAI CLIP ViT-L同样是一个只由Transformer模块组成的模型,一共有12个CLIPEncoder模块,特征维度为768,模型参数大小是123M。
OpenCLIP ViT-bigG的优势在于模型结构更深,特征维度更大,特征提取能力更强,但是其两者的基本CLIPEncoder模块是一样的。
对于输入text,送入CLIP text encoder后得到最后的hidden states(即最后一个transformer block得到的特征),其特征维度大小为77x768(77是token的数量),这个细粒度的text embeddings将以cross attention的方式送入UNet中。在transofmers库中,可以如下使用CLIP text encoder:
from transformers import CLIPTextModel, CLIPTokenizer
text_encoder = CLIPTextModel.from_pretrained("runwayml/stable-diffusion-v1-5", subfolder="text_encoder").to("cuda")
# text_encoder = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14").to("cuda")
tokenizer = CLIPTokenizer.from_pretrained("runwayml/stable-diffusion-v1-5", subfolder="tokenizer")
# tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
# 对输入的text进行tokenize,得到对应的token ids
prompt = "a photograph of an astronaut riding a horse"
text_input_ids = text_tokenizer(
prompt,
padding="max_length",
max_length=tokenizer.model_max_length,
truncation=True,
return_tensors="pt"
).input_ids
# 将token ids送入text model得到77x768的特征
text_embeddings = text_encoder(text_input_ids.to("cuda"))[0]
值得注意的是,这里的tokenizer最大长度为77(CLIP训练时所采用的设置),当输入text的tokens数量超过77后,将进行截断,如果不足则进行paddings,这样将保证无论输入任何长度的文本(甚至是空文本)都得到77x768大小的特征。 在训练SD的过程中,CLIP text encoder模型是冻结的。在早期的工作中,比如OpenAI的GLIDE和latent diffusion中的LDM均采用一个随机初始化的tranformer模型来提取text的特征,但是最新的工作都是采用预训练好的text model。比如谷歌的Imagen采用纯文本模型T5 encoder来提出文本特征,而SD则采用CLIP text encoder,预训练好的模型往往已经在大规模数据集上进行了训练,它们要比直接采用一个从零训练好的模型要好。
与传统深度学习中的模型融合类似,Stable Diffusion XL分别提取两个Text Encoder的倒数第二层特征,并进行concat操作作为文本条件(Text Conditioning)。其中OpenCLIP ViT-bigG的特征维度为77x1280,而CLIP ViT-L的特征维度是77x768,所以输入总的特征维度是77x2048(77是最大的token数),再通过Cross Attention模块将文本信息传入Stable Diffusion XL的训练过程与推理过程中。
1.5 U-net
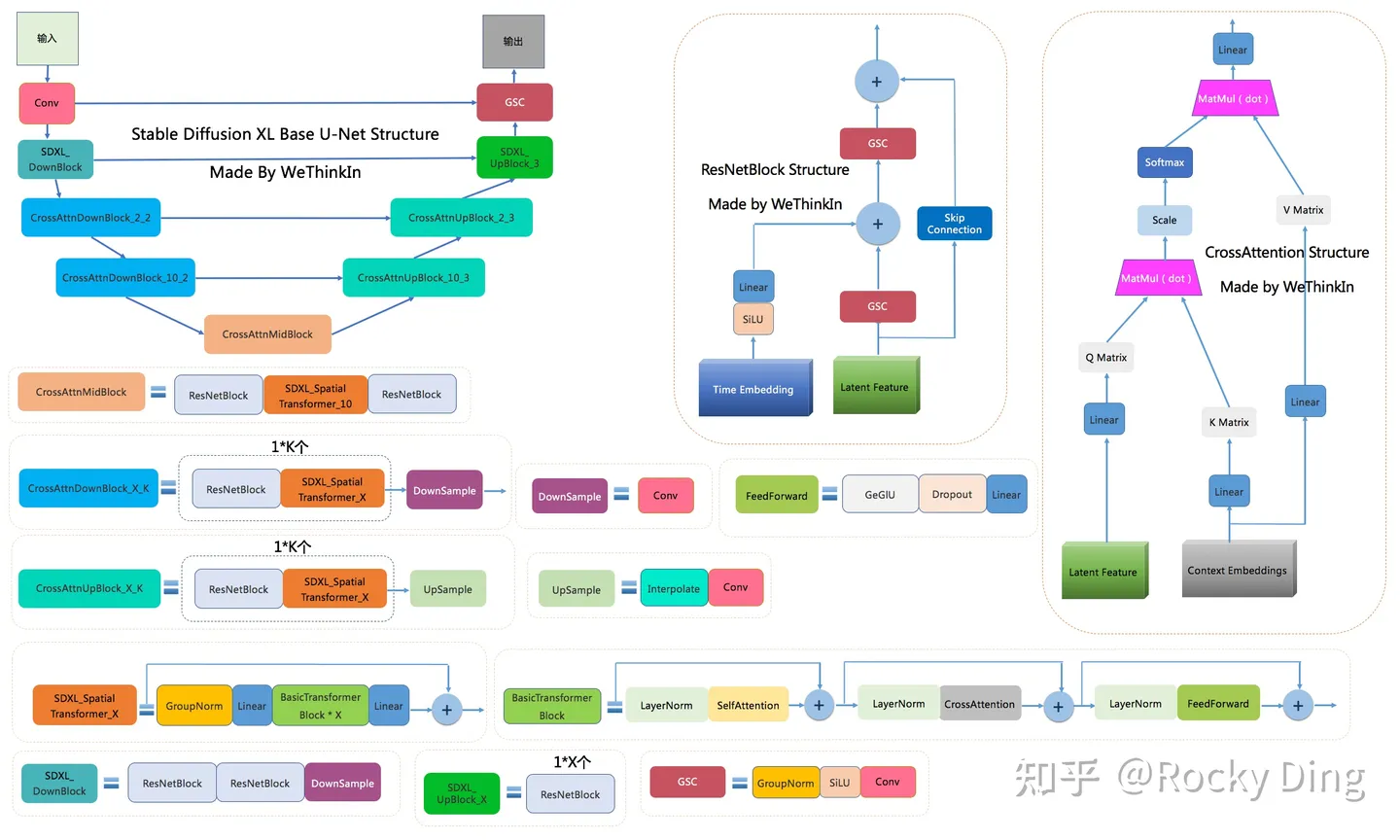
- GSC模块:Stable Diffusion Base XL U-Net中的最小组件之一,由GroupNorm+SiLU+Conv三者组成。
- DownSample模块:Stable Diffusion Base XL U-Net中的下采样组件,使用了Conv(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))进行采下采样。
- UpSample模块:Stable Diffusion Base XL U-Net中的上采样组件,由插值算法(nearest)+Conv组成。
- ResNetBlock模块:借鉴ResNet模型的“残差结构”,让网络能够构建的更深的同时,将Time Embedding信息嵌入模型。
- CrossAttention模块:将文本的语义信息与图像的语义信息进行Attention机制,增强输入文本Prompt对生成图片的控制。
- SelfAttention模块:SelfAttention模块的整体结构与CrossAttention模块相同,这是输入全部都是图像信息,不再输入文本信息。
- FeedForward模块:Attention机制中的经典模块,由GeGlU+Dropout+Linear组成。
- BasicTransformer Block模块:由LayerNorm+SelfAttention+CrossAttention+FeedForward组成,是多重Attention机制的级联,并且每个Attention机制都是一个“残差结构”。通过加深网络和多Attention机制,大幅增强模型的学习能力与图文的匹配能力。
- SDXL_Spatial Transformer_X模块:由GroupNorm+Linear+X个BasicTransformer Block+Linear构成,同时ResNet模型的“残差结构”依旧没有缺席。
- SDXL_DownBlock模块:由ResNetBlock+ResNetBlock+DownSample组成。
- SDXL_UpBlock_X模块:由X个ResNetBlock模块组成。
- CrossAttnDownBlock_X_K模块:是Stable Diffusion XL Base U-Net中Encoder部分的主要模块,由K个(ResNetBlock模块+SDXL_Spatial Transformer_X模块)+DownSample模块组成。
- CrossAttnUpBlock_X_K模块:是Stable Diffusion XL Base U-Net中Decoder部分的主要模块,由K个(ResNetBlock模块+SDXL_Spatial Transformer_X模块)+UpSample模块组成。
- CrossAttnMidBlock模块:是Stable Diffusion XL Base U-Net中Encoder和ecoder连接的部分,由ResNetBlock+SDXL_Spatial Transformer_10+ResNetBlock组成。
可以看到,其中增加的SDXL_Spatial Transformer_X模块(主要包含Self Attention + Cross Attention + FeedForward)数量占新增参数量的主要部分,在上表中已经用红色框圈出。U-Net的Encoder和Decoder结构也从原来的4stage改成3stage([1,1,1,1] -> [0,2,10]),说明SDXL只使用两次下采样和上采样,而之前的SD系列模型都是三次下采样和上采样。并且比起Stable DiffusionV1/2,Stable Diffusion XL在第一个stage中不再使用Spatial Transformer Blocks,而在第二和第三个stage中大量增加了Spatial Transformer Blocks(分别是2和10),那么这样设计有什么好处呢?
首先,在第一个stage中不使用SDXL_Spatial Transformer_X模块,可以明显减少显存占用和计算量。然后在第二和第三个stage这两个维度较小的feature map上使用数量较多的SDXL_Spatial Transformer_X模块,能在大幅提升模型整体性能(学习能力和表达能力)的同时,优化了计算成本。整个新的SDXL Base U-Net设计思想也让SDXL的Base出图分辨率提升至1024x1024。在参数保持一致的情况下,Stable Diffusion XL生成图片的耗时只比Stable Diffusion多了20%-30%之间,这个拥有2.6B参数量的模型已经足够伟大。
在SDXL U-Net的Encoder结构中,包含了两个CrossAttnDownBlock结构和一个SDXL_DownBlock结构;在Decoder结构中,包含了两个CrossAttnUpBlock结构和一个SDXL_UpBlock结构;与此同时,Encoder和Decoder中间存在Skip Connection,进行信息的传递与融合。
BasicTransformer Block模块是整个框架的基石,由SelfAttention,CrossAttention和FeedForward三个组件构成,并且使用了循环残差模式,让SDXL Base U-Net不仅可以设计的更深,同时也具备更强的文本特征和图像体征的学习能力。
Stable Diffusion XL中的Text Condition信息由两个Text Encoder提供(OpenCLIP ViT-bigG和OpenAI CLIP ViT-L),通过Cross Attention组件嵌入,作为K Matrix和V Matrix。与此同时,图片的Latent Feature作为Q Matrix。
1.5 Refiner模型
DeepFloyd和StabilityAI联合开发的DeepFloyd IF是一种基于像素的文本到图像三重级联扩散模型,大大提升了扩散模型的图像生成能力。
这次,Stable Diffusion XL终于也开始使用级联策略,在U-Net(Base)之后,级联Refiner模型,进一步提升生成图像的细节特征与整体质量。
通过级联模型提升生成图片的质量,可以说这是AIGC时代里的模型融合。和传统深度学习时代的多模型融合策略一样,不管是学术界,工业界还是竞赛界,都是“行业核武”般的存在。
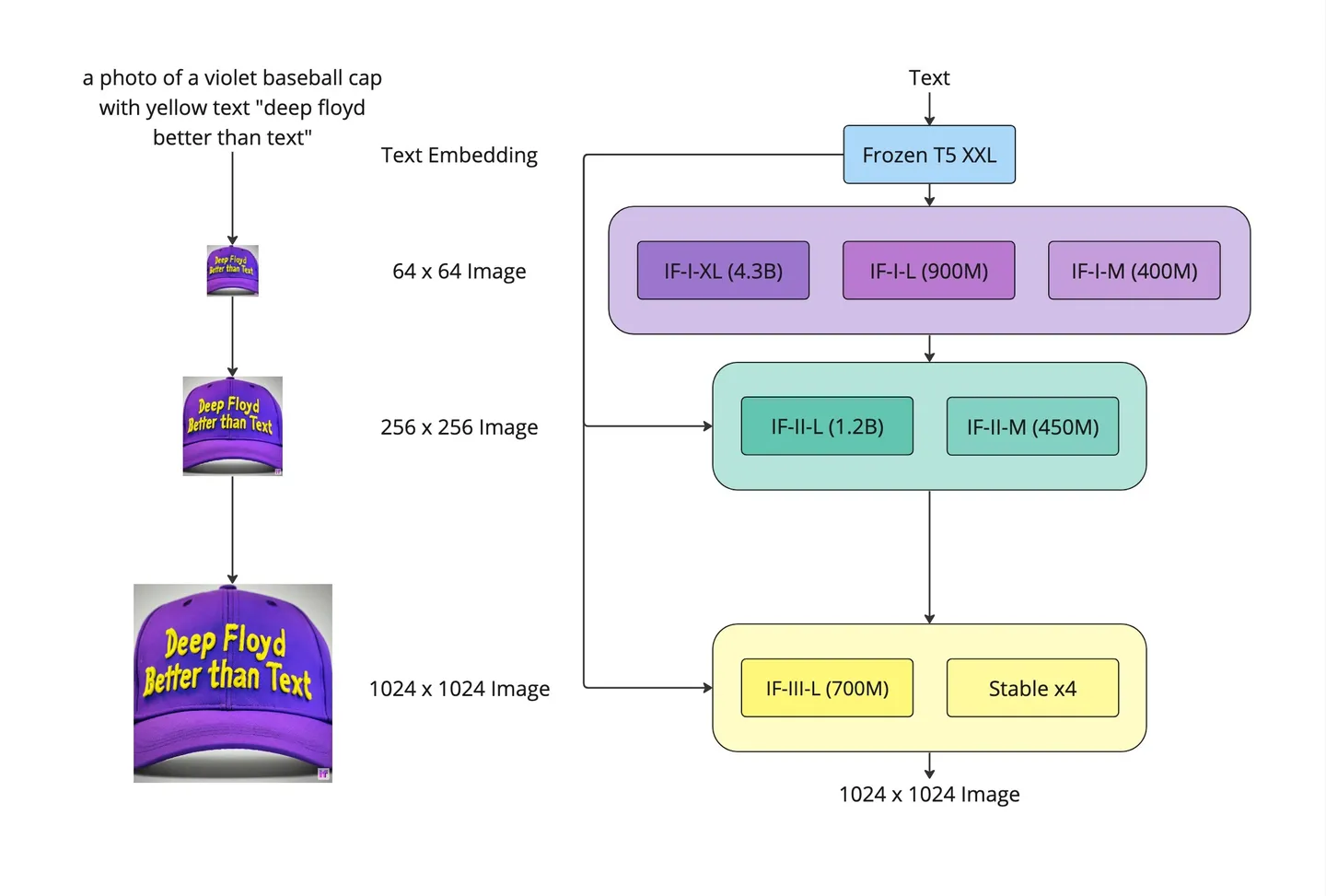
由于已经有U-Net(Base)模型生成了图像的Latent特征,所以Refiner模型的主要工作是在Latent特征进行小噪声去除和细节质量提升。
Refiner模型和Base模型一样是基于Latent的扩散模型,也采用了Encoder-Decoder结构,和U-Net兼容同一个VAE模型,不过Refiner模型的Text Encoder只使用了OpenCLIP ViT-bigG。
下图是Stable Diffusion XL Refiner模型的完整结构图
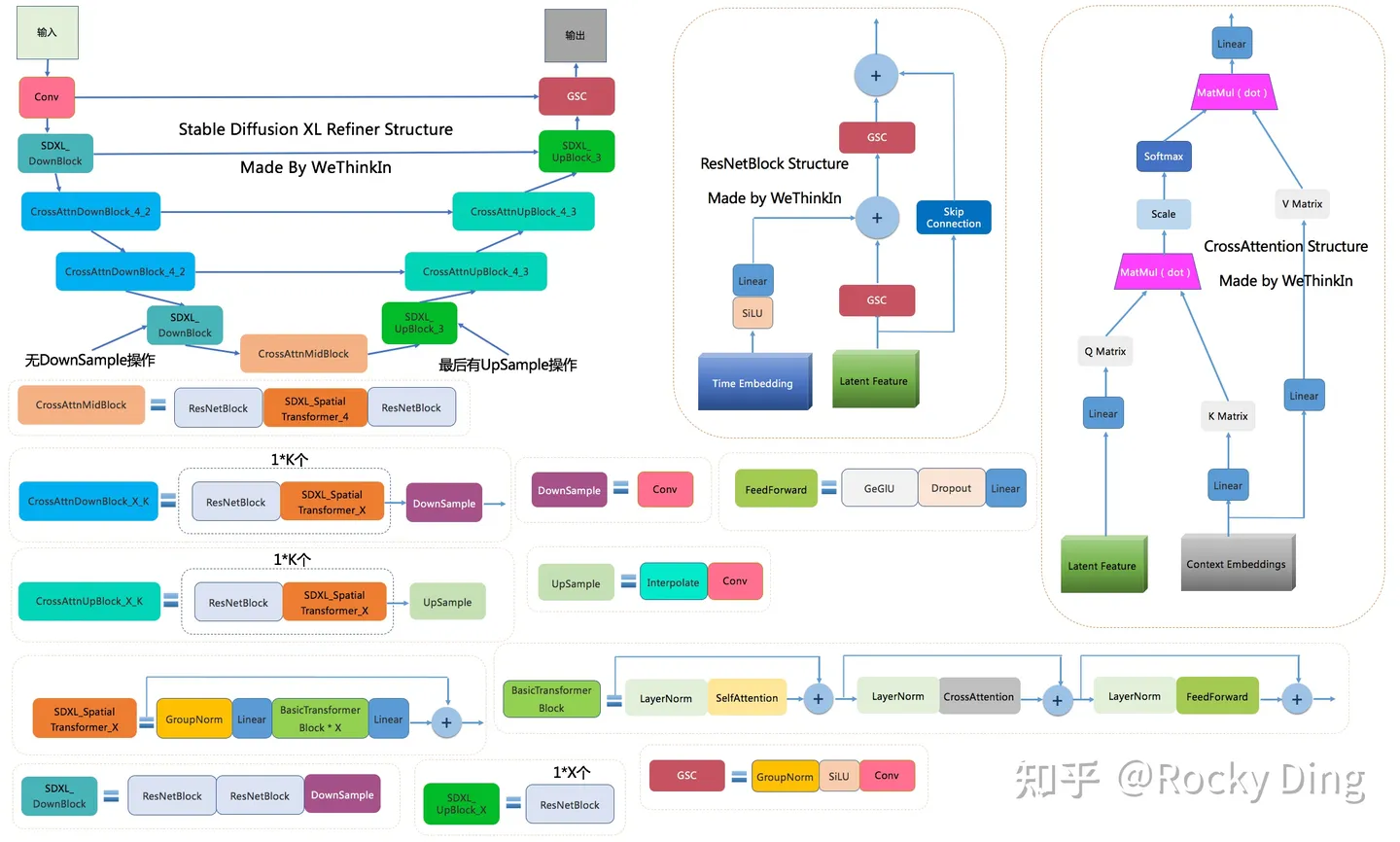
在Stable Diffusion XL推理阶段,输入一个prompt,通过VAE和U-Net(Base)模型生成Latent特征,接着给这个Latent特征加一定的噪音,在此基础上,再使用Refiner模型进行去噪,以提升图像的整体质量与局部细节。

可以看到,Refiner模型主要做了图像生成图像的工作,其具备很强的迁移兼容能力,可以作为Stable Diffusion,GAN,VAE等生成式模型的级联组件,不管是对学术界,工业界还是竞赛界,无疑都是一个无疑都是一个巨大利好。
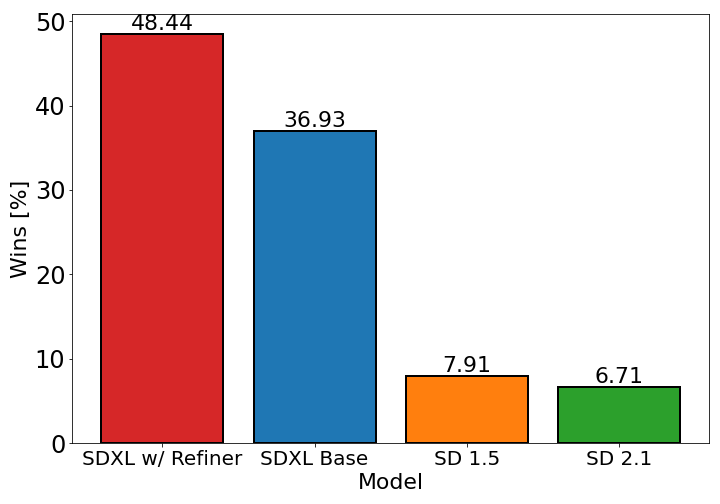
只使用U-Net(Base)模型,Stable Diffusion XL模型的效果已经大幅超过SD1.5和SD2.1,当增加Refiner模型之后,Stable Diffusion XL达到了更加优秀的图像生成效果。
2 常用的Stable Diffusion模型
2.1 checkpoint模型
checkpoint模型是真正意义上的Stable Diffusion模型,它们包含生成图像所需的一切(TextEncoder, U-net, VAE),不需要额外的文件。但是它们体积很大,通常为2G-7G。Stable Diffusion 作为专注于图像生成领域的大模型,它的目的并不是直接进行绘图,而是通过学习海量的图像数据来做预训练,提升模型整体的基础知识水平,这样就能以强大的通用性和实用性状态完成后续下游任务的应用。Stable Diffusion 官方模型的真正价值在于降低了模型训练的门槛,因为在现有大模型基础上训练新模型的成本要低得多。对特定图片生成任务来说,只需在官方模型基础上加上少量的文本图像数据,并配合微调模型的训练方法,就能得到应用于特定领域的定制模型。一方面训练成本大大降低,只需在本地用一张民用级显卡训练几小时就能获得稳定出图的定制化模型,另一方面,针对特定方向训练模型的理解和绘图能力更强,实际的出图效果反而有了极大的提升。
官方模型是在laion2B-en数据集上训练的,它是laion-5b数据集的一个子集,更具体的说它是laion-5b中的英文(文本为英文)数据集。laion-5b数据集是从网页数据Common Crawl中筛选出来的图像-文本对数据集,它包含5.85B的图像-文本对,其中文本为英文的数据量为2.32B,这就是laion2B-en数据集。
laion数据集中除了图片(下载URL,图像width和height)和文本(描述文本)的元信息外,还包含以下信息:
- similarity:使用CLIP ViT-B/32计算出来的图像和文本余弦相似度;
- pwatermark:使用一个图片水印检测器检测的概率值,表示图片含有水印的概率;
- punsafe:图片是否安全,或者图片是不是NSFW,使用基于CLIP的检测器来估计;
- AESTHETIC_SCORE:图片的美学评分(1-10),这个是后来追加的,首先选择一小部分图片数据集让人对图片的美学打分,然后基于这个标注数据集来训练一个打分模型,并对所有样本计算估计的美学评分。
上面是laion数据集的情况,下面我们来介绍SD训练数据集的具体情况,SD的训练是多阶段的(先在256x256尺寸上预训练,然后在512x512尺寸上精调),不同的阶段产生了不同的版本:
- SD v1.1:在laion2B-en数据集上以256x256大小训练237,000步,上面我们已经说了,laion2B-en数据集中256以上的样本量共1324M;然后在laion5B的高分辨率数据集以512x512尺寸训练194,000步,这里的高分辨率数据集是图像尺寸在1024x1024以上,共170M样本。
- SD v1.2:以SD v1.1为初始权重,在improved_aesthetics_5plus数据集上以512x512尺寸训练515,000步数,这个improved_aesthetics_5plus数据集上laion2B-en数据集中美学评分在5分以上的子集(共约600M样本),注意这里过滤了含有水印的图片(pwatermark>0.5)以及图片尺寸在512x512以下的样本。
- SD v1.3:以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上继续以512x512尺寸训练195,000步数,不过这里采用了CFG(以10%的概率随机drop掉text)。
- SD v1.4:以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上采用CFG以512x512尺寸训练225,000步数。
- SD v1.5:以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上采用CFG以512x512尺寸训练595,000步数。
其实可以看到SD v1.3、SD v1.4和SD v1.5其实是以SD v1.2为起点在improved_aesthetics_5plus数据集上采用CFG训练过程中的不同checkpoints,目前最常用的版本是SD v1.4和SD v1.5。 SD的训练是采用了32台8卡的A100机器(32 x 8 x A100_40GB GPUs),所需要的训练硬件还是比较多的,但是相比语言大模型还好。单卡的训练batch size为2,并采用gradient accumulation,其中gradient accumulation steps=2,那么训练的总batch size就是32x8x2x2=2048。训练优化器采用AdamW,训练采用warmup,在初始10,000步后学习速率升到0.0001,后面保持不变。至于训练时间,文档上只说了用了150,000小时,这个应该是A100卡时,如果按照256卡A100来算的话,那么大约需要训练25天左右。
Checkpoint 模型的常见训练方法叫 Dreambooth,该技术原本由谷歌团队基于自家的 Imagen 模型开发,后来经过适配被引入 Stable Diffusion 模型中,并逐渐被广泛应用。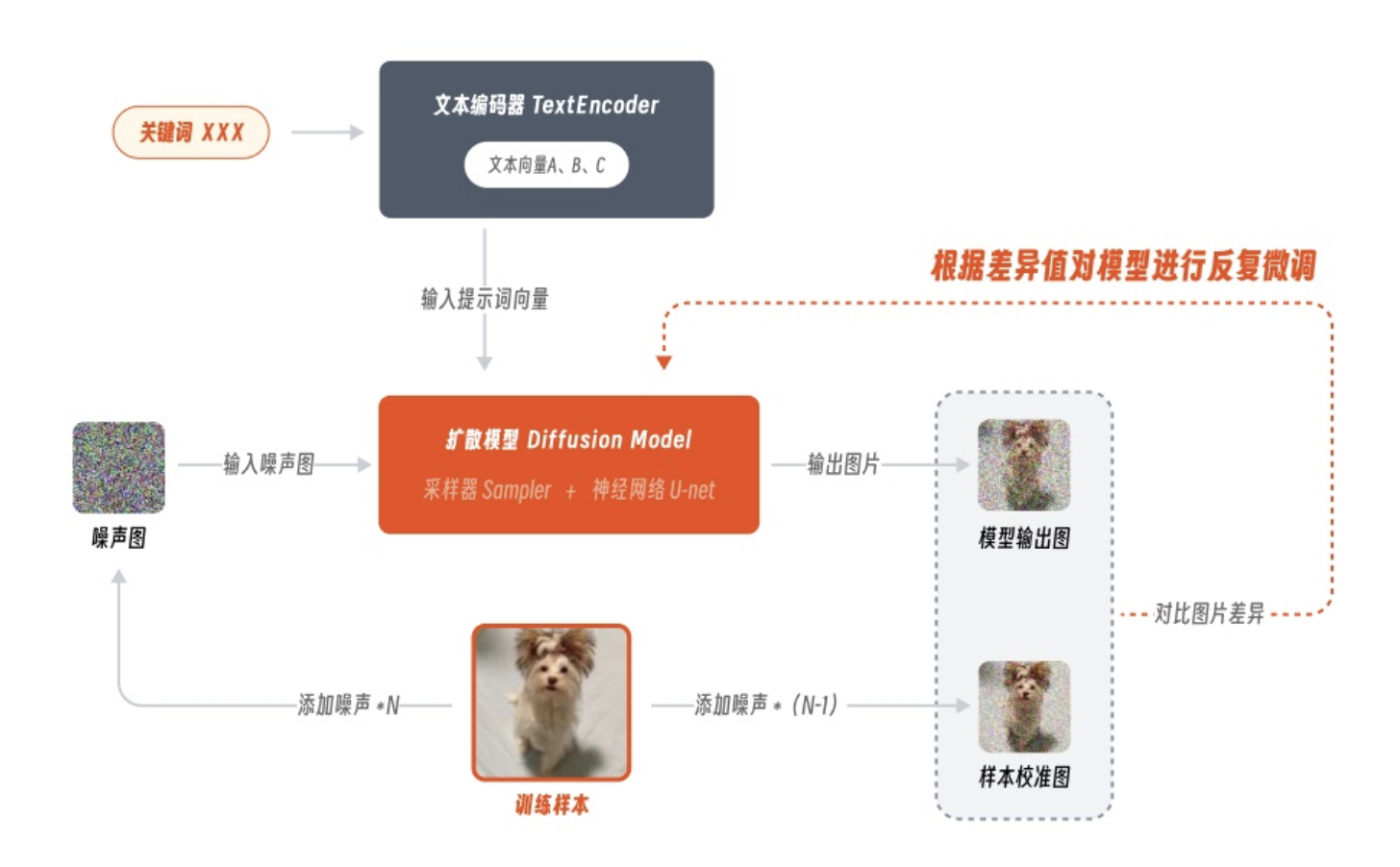
2.2 Textual lnversion
Textual lnversion(又叫Embedding)是定义新关键字以生成新人物或图片风格的小文件。Stable Diffusion 模型包含文本编码器、扩散模型和图像编码器 3 个部分,其中文本编码器 TextEncoder 的作用是将提示词转换成电脑可以识别的文本向量,而 Embedding 模型的原理就是通过训练将包含特定风格特征的信息映射在其中,这样后续在输入对应关键词时,模型就会自动启用这部分文本向量来进行绘制。它们很小,通常为10-100 KB。必须将它们与checkpoint模型一起使用。(2023-11-06时间段中实际应用中效果不佳,不推荐使用)
2.3 LoRA 模型
LoRA 模型是用于修改图片风格的checkpoint模型的小补丁文件。它们通常为10-200 MB。必须与checkpoint模型一起使用。LoRA 是 Low-Rank Adaptation Models 的缩写,意思是低秩适应模型。LoRA 原本并非用于 AI 绘画领域,它是微软的研究人员为了解决大语言模型微调而开发的一项技术,因此像 GPT3.5 包含了 1750 亿量级的参数,如果每次训练都全部微调一遍体量太大,而有了 lora 就可以将训练参数插入到模型的神经网络中去,而不用全面微调。通过这样即插即用又不破坏原有模型的方法,可以极大的降低模型的训练参数,模型的训练效率也会被显著提升。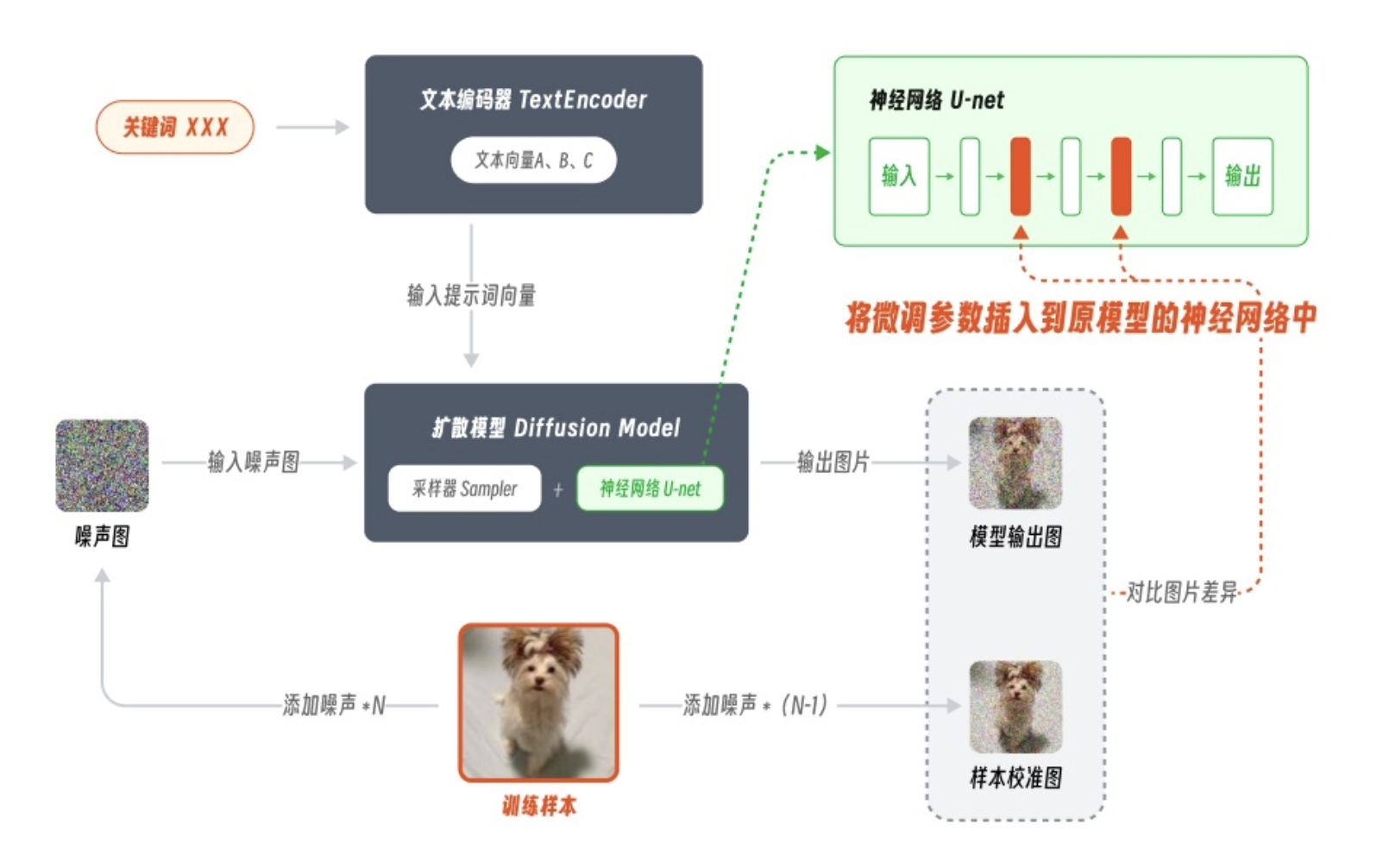
相较于 Dreambooth 全面微调模型的方法,LoRA 的训练参数可以减少上千倍,对硬件性能的要求也会急剧下降,如果说 Embeddings 像一张标注的便利贴,那 LoRA 就像是额外收录的夹页,在这个夹页中记录了更全面图片特征信息。
由于需要微调的参数量大大降低,LoRA 模型的文件大小通常在几百 MB,比 Embeddings 丰富了许多,但又没有 ckpt 那么臃肿。模型体积小、训练难度低、控图效果好,可以说是目前最热门的模型之一。
2.4 Hypernetwork 模型
Hypernetwork是添加到checkpoint模型中的附加网络模块。它们通常为5-300 MB。必须与checkpoint模型一起使用。它的原理是在扩散模型之外新建一个神经网络来调整模型参数,而这个神经网络也被称为超网络。因为 Hypernetwork 训练过程中同样没有对原模型进行全面微调,因此模型尺寸通常也在几十到几百 MB 不等。它的实际效果,我们可以将其简单理解为低配版的 LoRA,虽然超网络这名字听起来很厉害,但其实这款模型如今的风评并不出众,在国内已逐渐被 lora 所取代。因为它的训练难度很大且应用范围较窄,目前大多用于控制图像画风。所以除非是有特定的画风要求,否则还是建议优先选择 LoRA 模型来使用。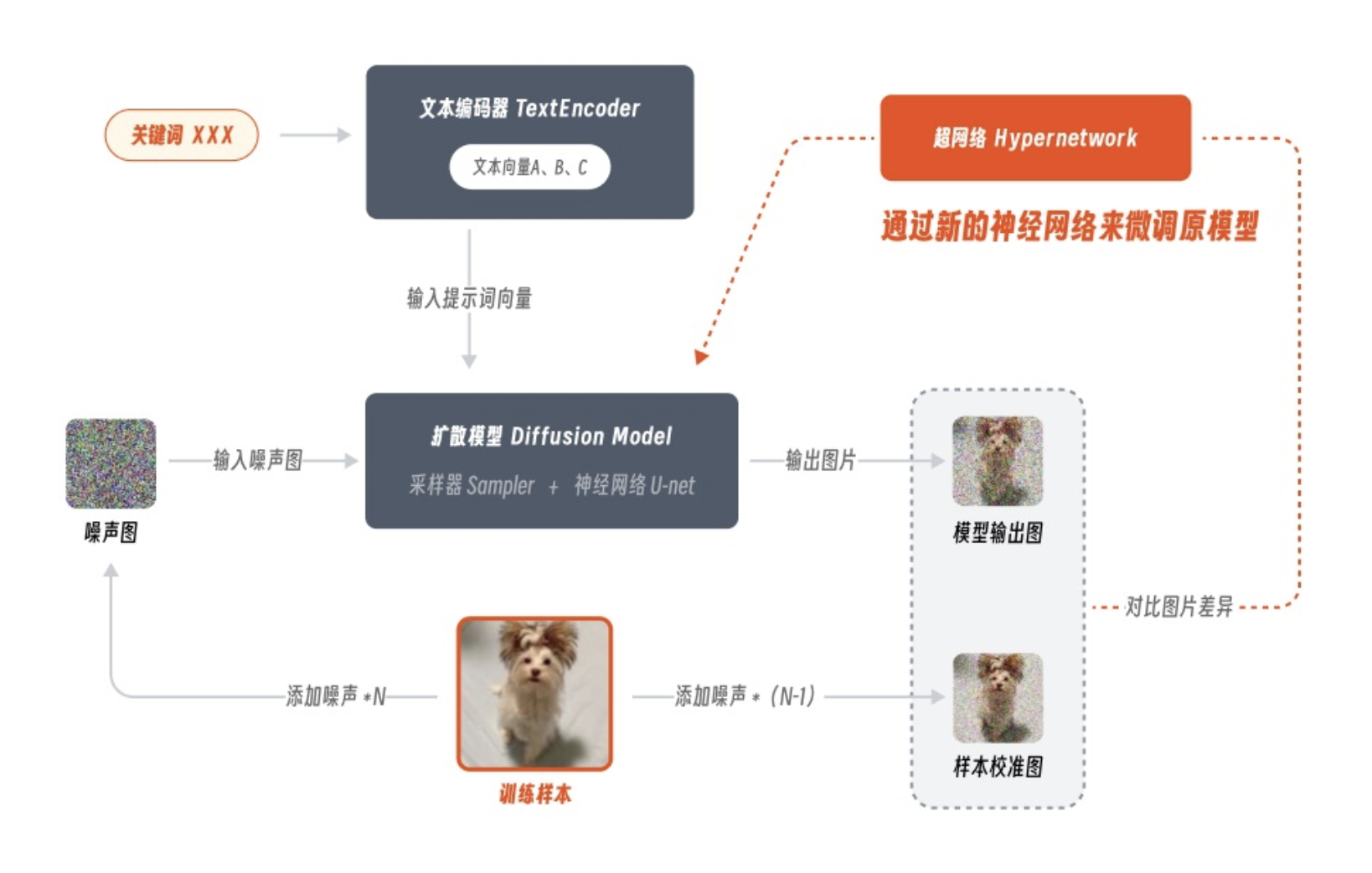
3 应用
SD的主要应用包括文生图,图生图以及图像inpainting。其中文生图是SD的基础功能:根据输入文本生成相应的图像,而图生图和图像inpainting是在文生图的基础上延伸出来的两个功能。
3.1 文生图
根据文本生成图像这是文生图的最核心的功能,下图为SD的文生图的推理流程图:首先根据输入text用text encoder提取text embeddings,同时初始化一个随机噪音noise(latent上的,512x512图像对应的noise维度为64x64x4),然后将text embeddings和noise送入扩散模型UNet中生成去噪后的latent,最后送入autoencoder的decoder模块得到生成的图像。
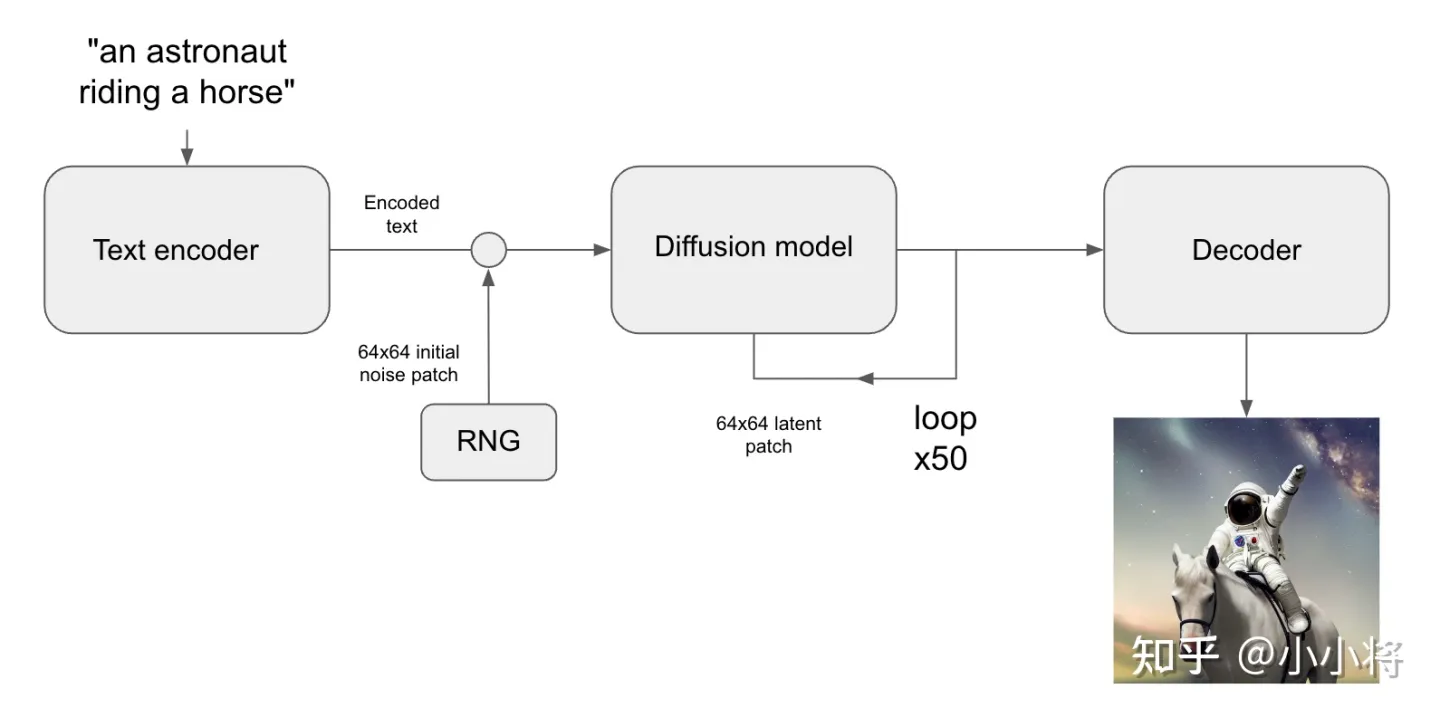
使用diffusers库,我们可以直接调用StableDiffusionPipeline来实现文生图,具体代码如下所示
import torch
from diffusers import StableDiffusionPipeline
from PIL import Image
# 组合图像,生成grid
def image_grid(imgs, rows, cols):
assert len(imgs) == rows*cols
w, h = imgs[0].size
grid = Image.new('RGB', size=(cols*w, rows*h))
grid_w, grid_h = grid.size
for i, img in enumerate(imgs):
grid.paste(img, box=(i%cols*w, i//cols*h))
return grid
# 加载文生图pipeline
pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", # 或者使用 SD v1.4: "CompVis/stable-diffusion-v1-4"
torch_dtype=torch.float16
).to("cuda")
# 输入text,这里text又称为prompt
prompts = [
"a photograph of an astronaut riding a horse",
"A cute otter in a rainbow whirlpool holding shells, watercolor",
"An avocado armchair",
"A white dog wearing sunglasses"
]
generator = torch.Generator("cuda").manual_seed(42) # 定义随机seed,保证可重复性
# 执行推理
images = pipe(
prompts,
height=512,
width=512,
num_inference_steps=50,
guidance_scale=7.5,
negative_prompt=None,
num_images_per_prompt=1,
generator=generator
).images
grid = image_grid(images, rows=1, cols=4)
grid
生成的图像效果如下所示:

这里可以通过指定width和height来决定生成图像的大小,前面说过SD最后是在512x512尺度上训练的,所以生成512x512尺寸效果是最好的,但是实际上SD可以生成任意尺寸的图片:一方面autoencoder支持任意尺寸的图片的编码和解码,另外一方面扩散模型UNet也是支持任意尺寸的latents生成的(UNet是卷积+attention的混合结构)。然而,生成512x512以外的图片会存在一些问题,比如生成低分辨率图像时,图像的质量大幅度下降,下图为同样的文本在256x256尺寸下的生成效果:

如果是生成512x512以上分辨率的图像,图像质量虽然没问题,但是可能会出现重复物体以及物体被拉长的情况,下图为分别为768x512和512x768尺寸下的生成效果,可以看到部分图像存在一定的问题:
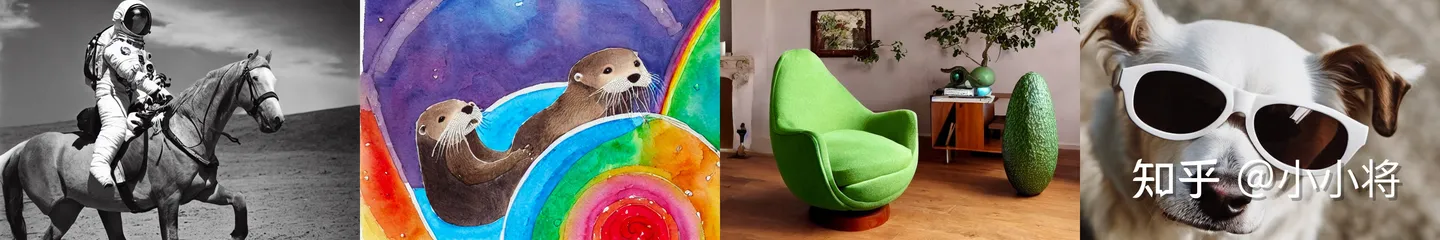

所以虽然SD的架构上支持任意尺寸的图像生成,但训练是在固定尺寸上(512x512),生成其它尺寸图像还是会存在一定的问题。解决这个问题的办法就相对比较简单,就是采用多尺度策略训练,比如NovelAI提出采用Aspect Ratio Bucketing策略来在二次元数据集上精调模型,这样得到的模型就很大程度上避免SD的这个问题,目前大部分开源的基于SD的精调模型往往都采用类似的多尺度策略来精调。比如我们采用开源的dreamlike-diffusion-1.0模型(基于SD v1.5精调的),其生成的图像效果在变尺寸上就好很多。
3.1 图生图
图生图(image2image)是对文生图功能的一个扩展,这个功能来源于SDEdit这个工作,其核心思路也非常简单:给定一个笔画的色块图像,可以先给它加一定的高斯噪音(执行扩散过程)得到噪音图像,然后基于扩散模型对这个噪音图像进行去噪,就可以生成新的图像,但是这个图像在结构和布局和输入图像基本一致。
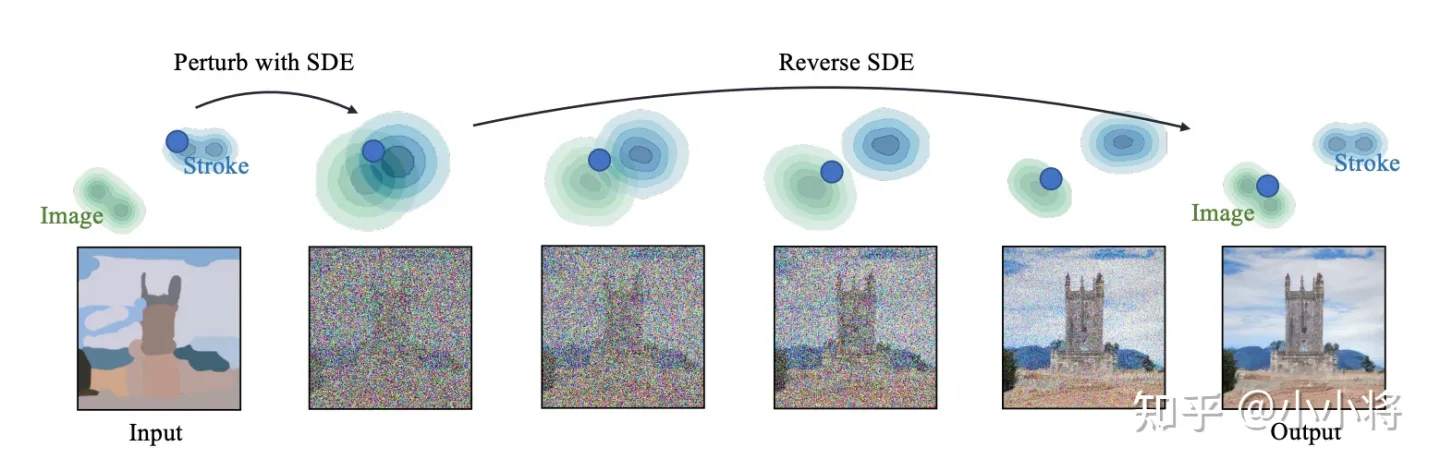
对于SD来说,图生图的流程图如下所示,相比文生图流程来说,这里的初始latent不再是一个随机噪音,而是由初始图像经过autoencoder编码之后的latent加高斯噪音得到,这里的加噪过程就是扩散过程。要注意的是,去噪过程的步数要和加噪过程的步数一致,就是说你加了多少噪音,就应该去掉多少噪音,这样才能生成想要的无噪音图像。
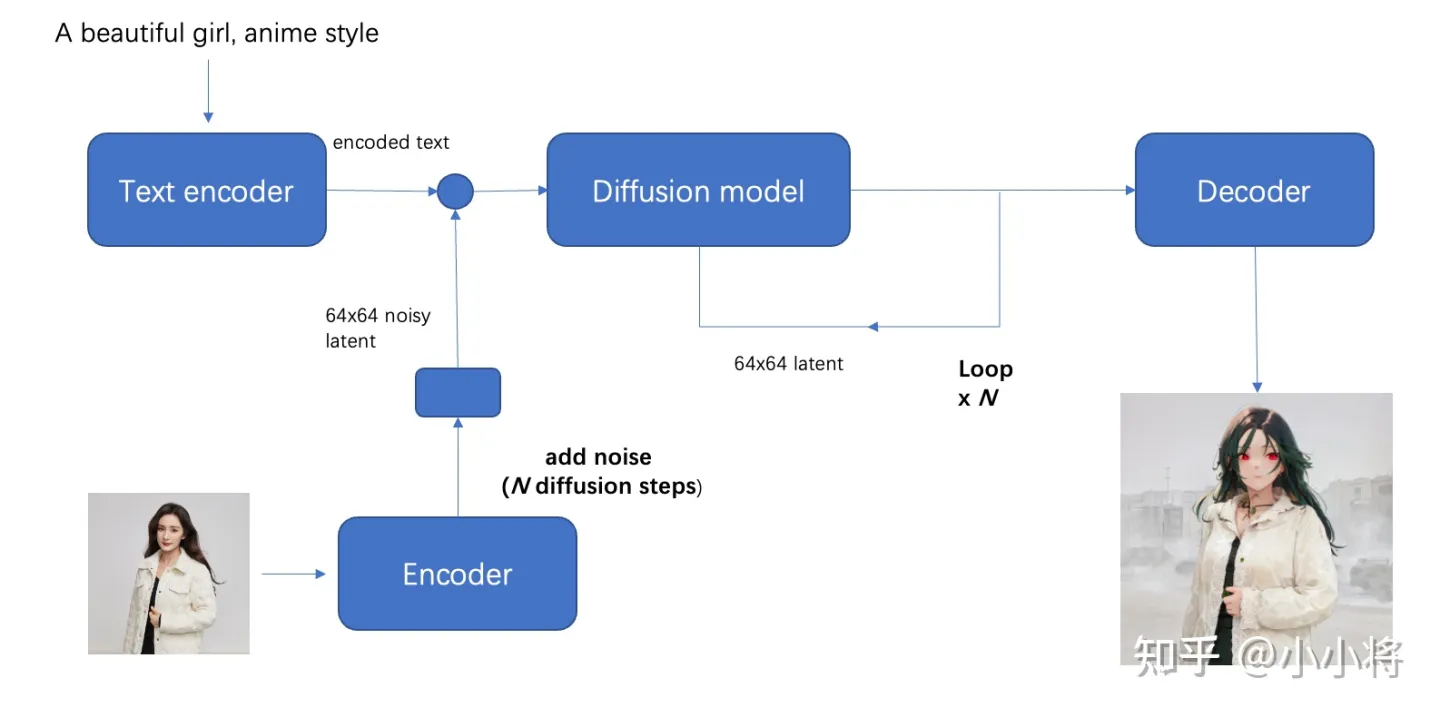
在diffusers中,我们可以使用StableDiffusionImg2ImgPipeline来实现文生图,具体代码如下所示:
import torch
from diffusers import StableDiffusionImg2ImgPipeline
from PIL import Image
# 加载图生图pipeline
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
# 读取初始图片
init_image = Image.open("init_image.png").convert("RGB")
# 推理
prompt = "A fantasy landscape, trending on artstation"
generator = torch.Generator(device="cuda").manual_seed(2023)
image = pipe(
prompt=prompt,
image=init_image,
strength=0.8,
guidance_scale=7.5,
generator=generator
).images[0]
image
相比文生图的pipeline,图生图的pipeline还多了一个参数strength,这个参数介于0-1之间,表示对输入图片加噪音的程度,这个值越大加的噪音越多,对原始图片的破坏也就越大,当strength=1时,其实就变成了一个随机噪音,此时就相当于纯粹的文生图pipeline了。下面展示了一个具体的实例,这里的第一张图为输入的初始图片,它是一个笔画的色块,我们可以通过图生图将它生成一幅具体的图像,其中第2张图和第3张图的strength分别是0.5和0.8,可以看到当strength=0.5时,生成的图像和原图比较一致,但是就比较简单了,当strength=0.8时,生成的图像偏离原图更多,但是图像的质感有一个明显的提升。

图生图这个功能一个更广泛的应用是在风格转换上,比如给定一张人像,想生成动漫风格的图像。这里我们可以使用动漫风格的开源模型anything-v4.0,它是基于SD v1.5在动漫风格数据集上finetune的,使用它可以更好地利用图生图将人物动漫化。下面的第1张为输入人物图像,采用的prompt为”masterpiece, best quality, 1girl, red hair, medium hair, green eyes”,后面的图像是strength分别为0.3-0.9下生成的图像。可以看到在不同的strength下图像有不同的生成效果,其中strength=0.6时效果最好。

3.3 图像inpainting
最后我们一项功能是图像inpainting,它和图生图一样也是文生图功能的一个扩展。SD的图像inpainting不是用在图像修复上,而是主要用在图像编辑上:给定一个输入图像和想要编辑的区域mask,我们想通过文生图来编辑mask区域的内容。SD的图像inpainting原理可以参考论文Blended Latent Diffusion,其主要原理图如下所示:
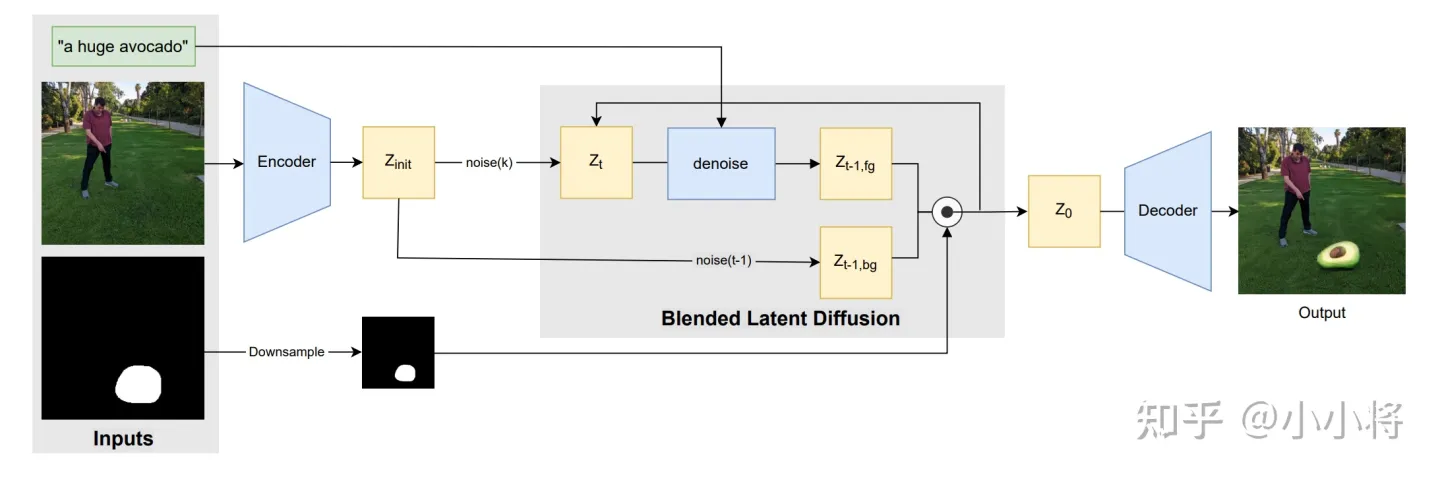
它和图生图一样:首先将输入图像通过autoencoder编码为latent,然后加入一定的高斯噪音生成noisy latent,再进行去噪生成图像,但是这里为了保证mask以外的区域不发生变化,在去噪过程的每一步,都将扩散模型预测的noisy latent用真实图像同level的nosiy latent替换。 在diffusers中,使用StableDiffusionInpaintPipelineLegacy可以实现文本引导下的图像inpainting,具体代码如下所示:
import torch
from diffusers import StableDiffusionInpaintPipelineLegacy
from PIL import Image
# 加载inpainting pipeline
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionInpaintPipelineLegacy.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
# 读取输入图像和输入mask
input_image = Image.open("overture-creations-5sI6fQgYIuo.png").resize((512, 512))
input_mask = Image.open("overture-creations-5sI6fQgYIuo_mask.png").resize((512, 512))
# 执行推理
prompt = ["a mecha robot sitting on a bench", "a cat sitting on a bench"]
generator = torch.Generator("cuda").manual_seed(0)
with torch.autocast("cuda"):
images = pipe(
prompt=prompt,
image=input_image,
mask_image=input_mask,
num_inference_steps=50,
strength=0.75,
guidance_scale=7.5,
num_images_per_prompt=1,
generator=generator,
).images
4 实践
4.1 主流方法
目前可以在本地运行SDXL的主流方法为
- AUTOMATIC1111’s Stable Diffusion WebUI 基于gradio框架实现了SD的快速部署,不仅支持SD的最基础的文生图、图生图以及图像inpainting功能,还支持SD的其它拓展功能,很多基于SD的拓展应用可以用插件的方式安装在webui上。本说明书将使用此方法。
- ComfyUI 上手较难,node based interface,但生成速度非常快,比 AUTOMATIC1111 快 5-10 倍。允许使用两种不同的正向提示。
4.2 AUTOMATIC1111使用方法
4.2.1 Install AUTOMATIC1111 on Linux
# Create environment
conda create -n sd python=3.10.6
# Activate environment
conda activate sd
# Validate environment is selected
conda info --env
# Start local webserver
./webui.sh
# Wait for "Running on local URL: http://127.0.0.1:7860" and open that URI.
4.2.2 下载模型
下载base model 和 refiner model(每个~6GB)huggingface网站
-
将base model 和 refiner model放置在./model/stable-diffusion-webui/中
-
运行
./webui.sh --xformers -
打开url链接http://127.0.0.1:7860,在以下的ui选择框中可以选择对应的model
base model作为训练或推理时的底模使用
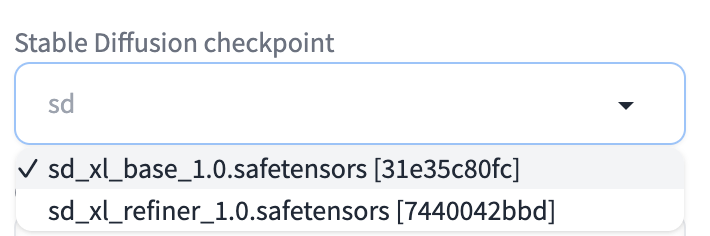
refiner model仅在推理时使用

4.2.2 调参生图
-
Resolution: 1024 x 1024
-
Tiling 生成一个可以平铺的图像;
-
Highres. fix 使用两个步骤的过程进行生成,以base model创建图像,然后在不改变构图的情况下以refine model改进其中的细节,选择该部分会有两个新的参数
-
Switch at: 切换位置,该值控制在哪一步切换到refiner model。例如,在 0.5 时切换并使用 40 个步骤表示在前 20 个步骤中使用base model,在后 20 个步骤中使用refiner model。
如果切换到 1,则只使用base model。
-
Sampling Steps:经验最优值为30 steps and switch at 0.6。diffusion model 生成图片的迭代步数,每多一次迭代都会给 AI 更多的机会去比对 prompt 和 当前结果,去调整图片。更高的步数需要花费更多的计算时间,也相对更贵。但不一定意味着更好的结果。

-
Clip skip: 1 or 2
-
Sampling method 扩散去噪算法的采样模式,会带来不一样的效果,ddim 和 pms(plms) 的结果差异会很大,很多人还会使用euler,具体没有系统测试。
-
Tiling 生成一个可以平铺的图像;
Highres. fix 使用两个步骤的过程进行生成,以较小的分辨率创建图像,然后在不改变构图的情况下改进其中的细节,选择该部分会有两个新的参数
-
CFG scale: 7。越大时,生成的图像应该会和输入文本更一致,当guidance_scale较低时生成的图像效果是比较差的,当guidance_scale在7~9时,生成的图像效果是可以的,当采用更大的guidance_scale比如11,图像的色彩过饱和而看起来不自然,过大的guidance_scale之所以出现问题,主要是由于训练和测试的不一致,过大的guidance_scale会导致生成的样本超出范围。所以SD默认采用的guidance_scale为7.5。
下图为guidance_scale为1,3,5,7,9和11下生成的图像对比

-
Seed 种子数,只要种子数一样,参数一致、模型一样图像就能重新被绘制;
-
Scale latent 在潜空间中对图像进行缩放。另一种方法是从潜在的表象中产生完整的图像,将其升级,然后将其移回潜在的空间。
-
Denoising strength: 决定算法对图像内容的保留程度。在0处,什么都不会改变,而在1处,会得到一个不相关的图像。一般大于0.7出来的都是新效果,小于0.3基本就会原图缝缝补补;

-
增加选择已训练的lora和hypernetwork模型可以实现更多自定义功能
例如,把训练好的 LoRA 模型全部放入 LoRA 模型目录 stable-diffusion-webui/models/Lora。
tips:使用XYZ plot 脚本
-
在 Stable Diffusion WebUI 页面最底部的脚本栏中调用 XYZ plot 脚本,设置模型对比参数。
-
其中 X 轴类型和 Y 轴类型都选择「提示词搜索/替换」Prompt S/R。
X 轴值输入:NUM,000001,000002,000003,000004,000005,对应模型序号
Y 轴值输入:STRENGTH,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1,对应模型权重值
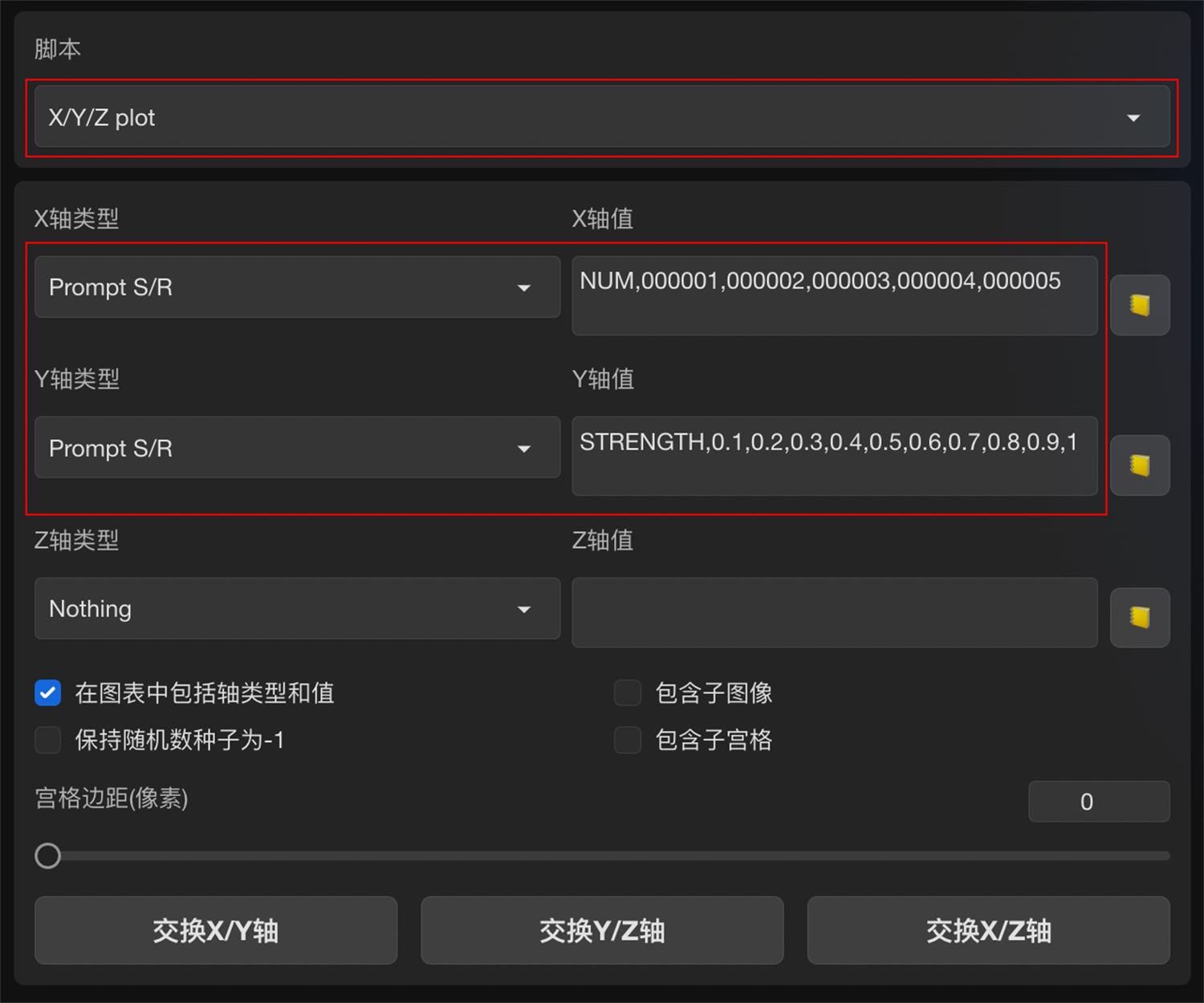
- 把引入的 LoRA 模型提示词,改成变量模式,如: 改成 ,NUM 变量代表模型序号,STRENGTH 变量代表权重值。

- 通过对比生成结果,选出表现最佳的模型和权重值。

4.3 训练自定义模型
4.3.1 准备数据集
根据需要训练的标签来命名文件夹,例如选取的训练标签名称有:qzy, lsbr, flawless, flawed, fold, spot
文件存放的示意结构如下
weipin
├── qzy
│ ├── flawless
│ │ ├── xxx1.jpg
│ │ ├── xxx2.jpg
│ │ ├── xxx3.jpg
│ ├── flawed
│ │ ├── fold
│ │ │ ├── xxx1.jpg
│ │ │ ├── xxx2.jpg
│ │ ├── spot
│ │ │ ├── xxx1.jpg
│ │ │ ├── xxx2.jpg
├── lsbr
│ ├── flawless
│ │ ├── xxx1.jpg
│ │ ├── xxx2.jpg
│ │ ├── xxx3.jpg
│ ├── flawed
│ │ ├── fold
│ │ │ ├── xxx1.jpg
│ │ │ ├── xxx2.jpg
│ │ ├── spot
│ │ │ ├── xxx1.jpg
│ │ │ ├── xxx2.jpg
每个末端文件夹中的图片建议数量为5-10张,使用filename.py将所有jpg文件重命名为母文件夹名_子文件夹名_数字编号的形式,如qzy_flawed_spot_数字编号并将所有图片文件归到一个文件夹下
train_output
├── qzy_flawed_spot_01.jpg
├── qzy_flawed_spot_02.jpg
├── qzy_flawed_spot_03.jpg
├── lsbr_flawless_01.jpg
####filename.py
import os
import shutil
def rename_and_copy_files(source_folder, destination_folder):
for root, dirs, files in os.walk(source_folder):
if files: # 只处理当前文件夹中包含文件的情况
folder_names = os.path.normpath(root).split(os.path.sep) # 获取文件夹路径并拆分为名称列表
new_name = "_".join(folder_names[1:]) # 使用下划线将文件夹名称拼接成新名称
i = 1 # 用于追踪重命名文件的数字
for file_name in files:
file_extension = os.path.splitext(file_name)[1] # 获取文件扩展名
new_file_name = f"{new_name}_{i:02d}{file_extension}" # 新文件名
i += 1
file_path = os.path.join(root, file_name)
new_file_path = os.path.join(root, new_file_name)
os.rename(file_path, new_file_path)
# 构建目标文件的完整路径
destination_file_path = os.path.join(destination_folder, new_file_name)
# 复制文件到目标文件夹
shutil.copy(new_file_path, destination_file_path)
source_folder = 'products' # 请替换为您的源文件夹路径
destination_folder = 'zx_train_output' # 请替换为您的目标文件夹路径
rename_and_copy_files(source_folder, destination_folder)
-
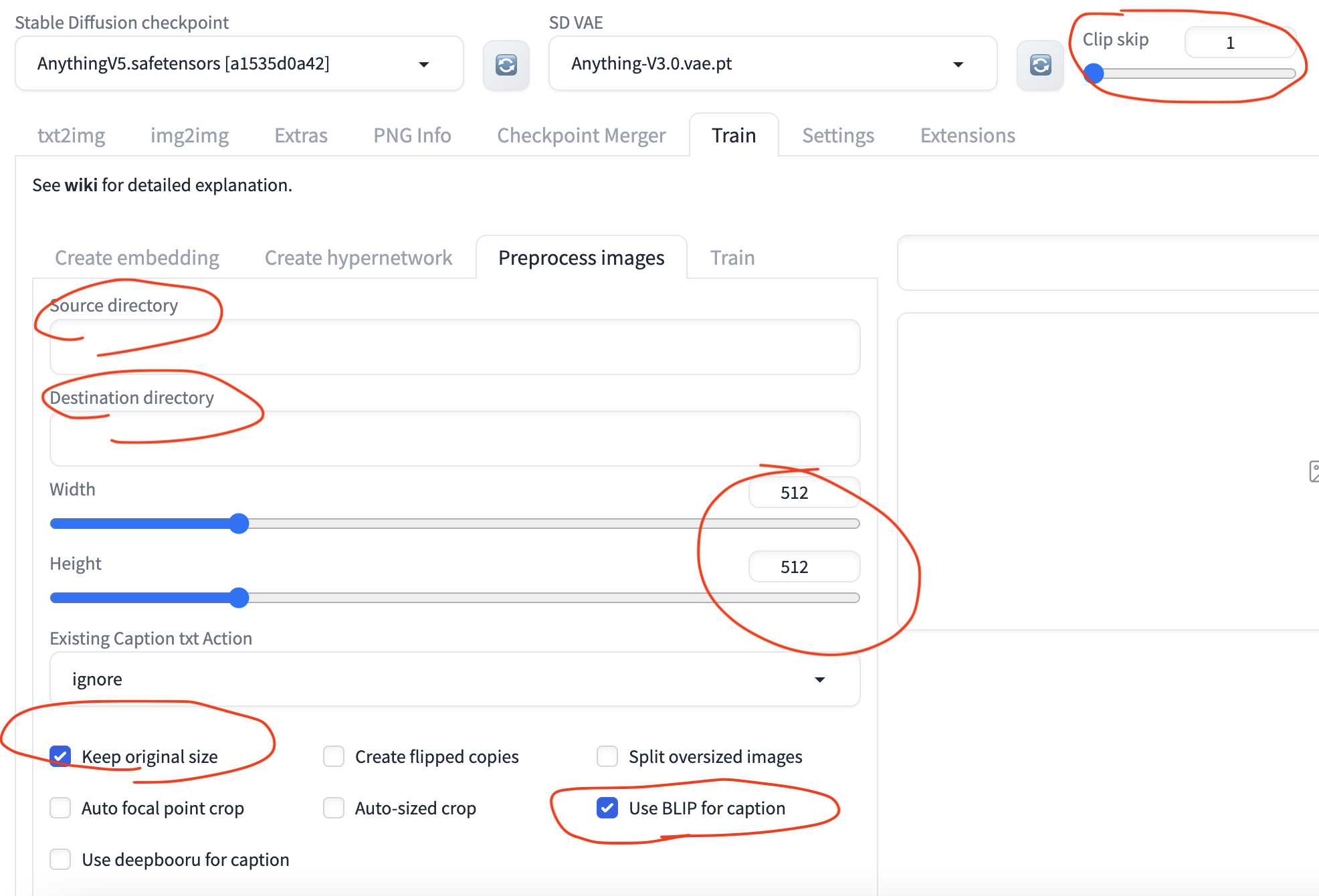
打开webui,使用图片剪裁功能将图片批量剪裁为512 x 512(hypernetwork训练)或1024 x 1024(lora训练)。根据blip处理规则自动重新命名图片文件,并生成与图片名一致的txt文件。
-
通过提取文件名中的关键词,将自动生成的txt文件中的内容修改为将要训练的标签,用逗号隔开。使用
fixtxt.py批量处理
### fixtxt.py
import os
# 定义要搜索的文件夹路径
folder_path = 'zx_train'
add = 'black background'
# 遍历文件夹中的所有文件
for root, dirs, files in os.walk(folder_path):
for file in files:
if file.endswith('.txt'):
file_path = os.path.join(root, file)
# 提取文件名中的关键词以_作为分隔符
keywords = os.path.splitext(file)[0].split('-')[-1].split('_')[:-1]
keywords.append(add)
# 将关键词以逗号分隔的形式写入原始文件
with open(file_path, 'w') as f:
f.write(', '.join(keywords))
经过以上捕捉,训练数据集准备完成
4.3.2 训练hypernetwork模型
可直接在AUTOMATIC1111’s Stable Diffusion WebUI中进行。
- 首先在Create hypernetwork中创建一个hypernetwork
- 然后在train中添加数据集开始训练
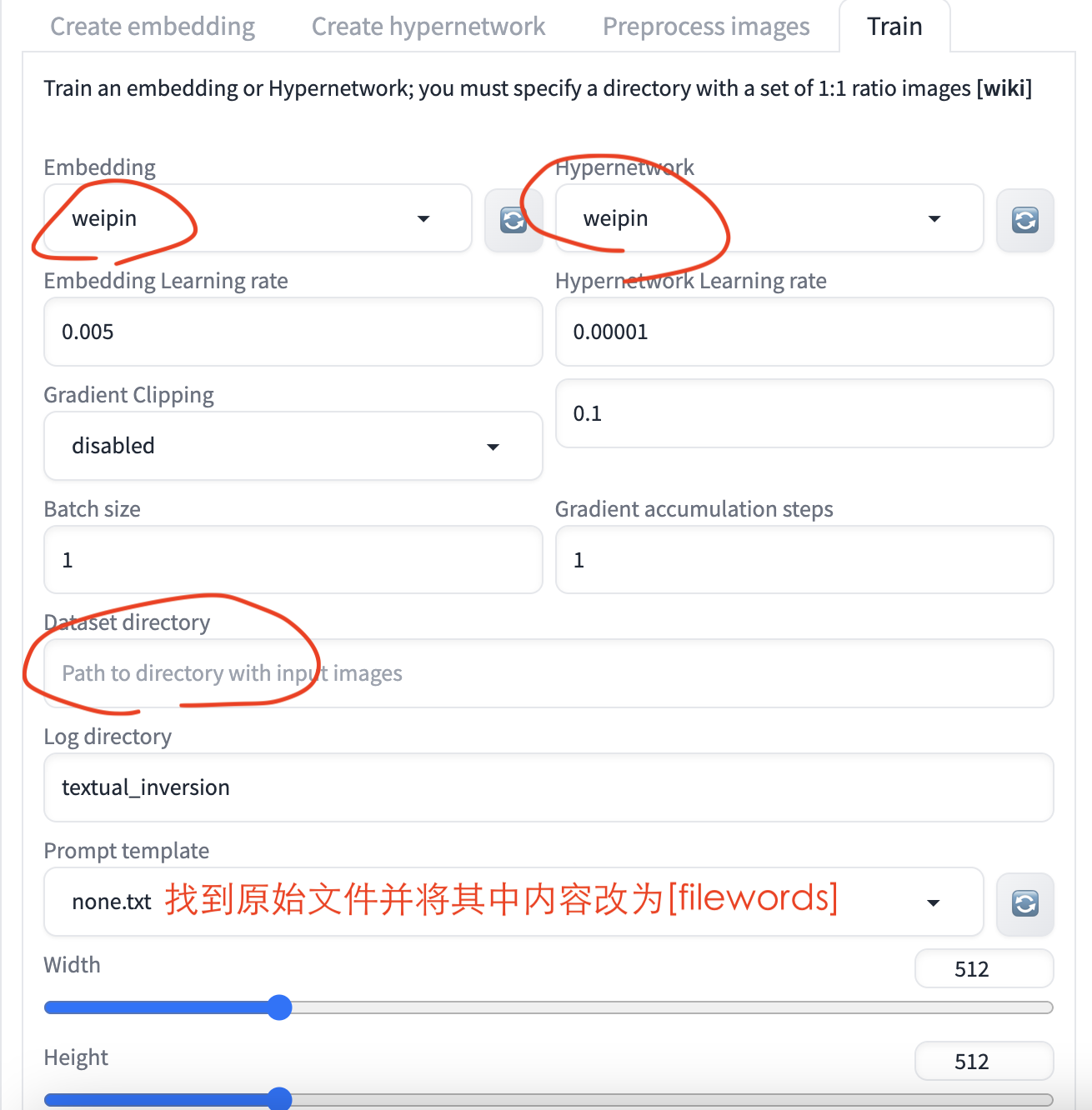
数据集结构为:
weipin
├── xxx1.jpg
├── xxx1.txt
├── xxx2.jpg
├── xxx2.txt
4.3.3 训练lora模型
lora模型的训练需要借助kohya_ss。
-
安装kohya_ss
# 1. clone repo git clone -b sdxl-dev https://github.com/bmaltais/kohya_ss.git # 2. install torch #cu117 conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia #cu118 conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia # 3.install requirements # install with file pip install -r requirements.txt # install without file pip install accelerate==0.19.0 albumentations==1.3.0 altair==4.2.2 dadaptation==3.1 diffusers[torch]==0.18.2 easygui==0.98.3 einops==0.6.0 fairscale==0.4.13 ftfy==6.1.1 gradio==3.36.1 huggingface-hub==0.15.1 lion-pytorch==0.0.6 lycoris_lora==1.8.0 invisible-watermark==0.2.0 open-clip-torch==2.20.0 opencv-python==4.7.0.68 prodigyopt==1.0 pytorch-lightning==1.9.0 rich==13.4.1 safetensors==0.3.1 timm==0.6.12 tk==0.1.0 toml==0.10.2 transformers==4.30.2 voluptuous==0.13.1 wandb==0.15.0 xformers==0.0.20 bitsandbytes==0.35.0 tensorboard==2.12.3 tensorflow==2.12.0 # if you are using linux pip install xformers==0.0.20 bitsandbytes==0.35.0 tensorboard==2.12.3 tensorflow==2.12.0 -
使用koyha_ss
-
在根目录下运行
./gui.sh -
初始运行会从huggingface.co网站下载各种预训练模型,如果下载失败,运行过程中,大概率报错。因此需要手动下载以下文件夹并根据报错信息将加载模型的路径改为本地的文件夹路径。
-
打开UI界面
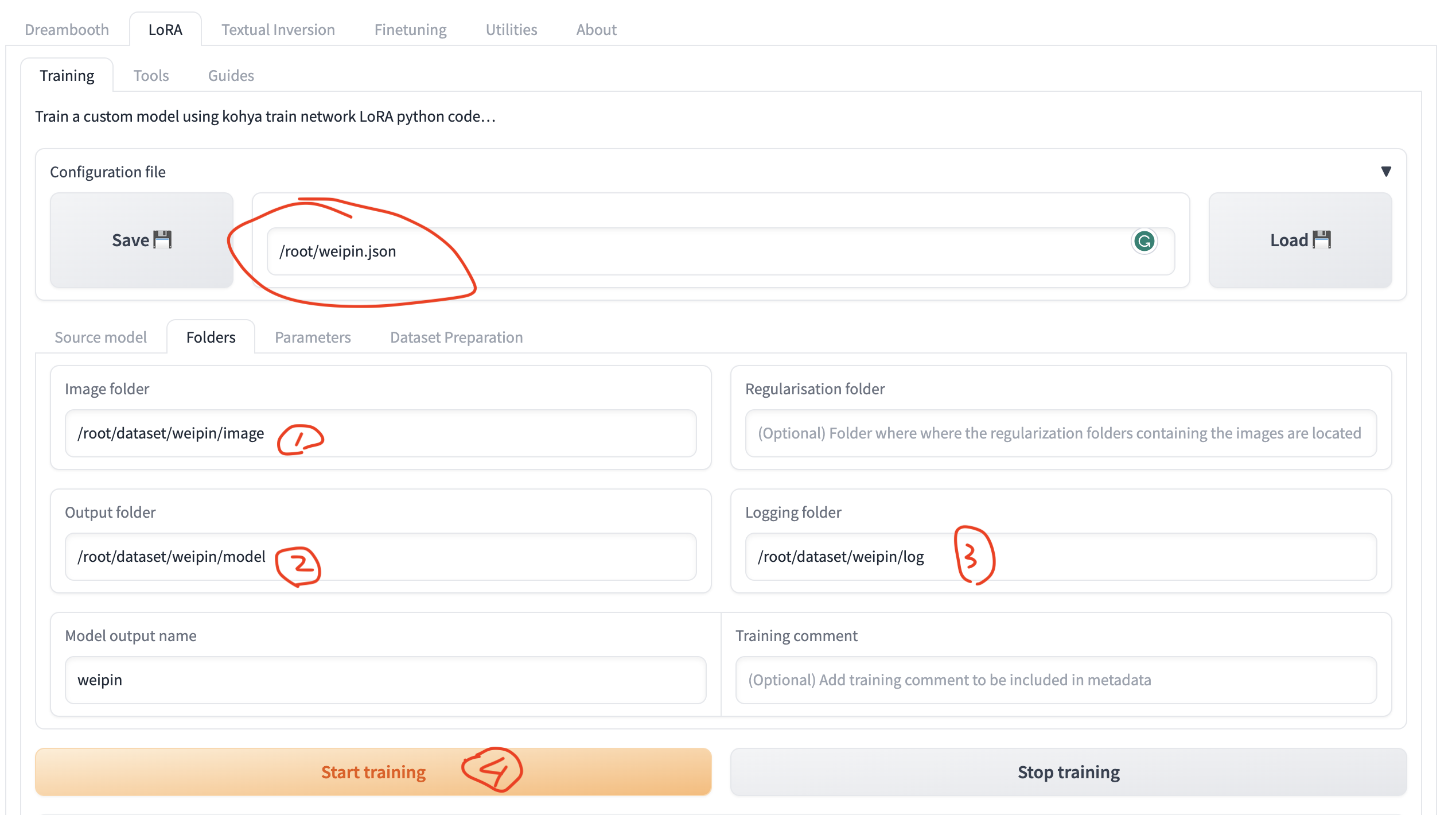
-
在LoRA界面中,选择weipin.json文件加载已经设置好的各项参数。weipin.json
-
设置训练数据集的路径并开始训练
训练数据集结构为:
weipin ├── image │ ├── 80_weipin │ │ ├── xxx1.jpg │ │ ├── xxx1.txt │ │ ├── xxx2.jpg │ │ ├── xxx2.txt ├── model ├── log其中80_weipin中的80代表训练图片80次,注意:image文件夹的结构不能改变。
- 若image文件夹中有.ipynb_checkpoints隐藏文件,则会报错,使用以下代码删除.ipynb_checkpoints。
rm -rf .ipynb_checkpoints find . -name ".ipynb_checkpoints" -exec rm -rf {} \; ## 这个在大文件运行后面就都删了 因为.ipynb_checkpoints是文件夹 需要加-rf循环地删除 -
-
LoRA的训练参数
- 底模:填入底模文件夹地址 /content/Lora/sd_model/,刷新加载底模。 resolution:训练分辨率,支持非正方形,但必须是 64 倍数。一般方图 1024x1024。
- batch_size:一次性送入训练模型的样本数,显存小推荐 1,24G取3-4,并行数量越大,训练速度越快。
- optimizer: 选择AdamW较多
- max_train_epoches:最大训练的 epoch 数,即模型会在整个训练数据集上循环训练的次数。如最大训练 epoch 为 10,那么训练过程中将会进行 10 次完整的训练集循环,一般可以设为 30。
- network_dim:线性 dim,代表模型大小,数值越大模型越精细,常用 128,如果设置为 128,则 LoRA 模型大小为 144M。
- network_alpha:线性 alpha,一般设置为比 Network Dim 小或者相同,通常将 network dim 设置为 128,network alpha 设置为 64。
- unet_lr:unet 学习率,经验数值为text_encode_lr的1/2,5e-05
- text_encoder_lr:文本编码器的学习率,1e-04
- lr_scheduler:学习率调度器,用来控制模型学习率的变化方式,constant_with_warmup。
- lr_warmup_steps:升温步数,仅在学习率调度策略为“constant_with_warmup”时设置,用来控制模型在训练前逐渐增加学习率的步数,可以设为10%。