
前期准备
点云数据需要使用bin格式储存,标注信息使用txt文件储存,可以使用LabelCloud进行3d标注。
基本数据格式
mmdetection3d支持多种预设的数据格式,如kitti, Lyft, nus, s3dis, scannet, semantickitti, sunrgbd, waymo等。在进行自定义数据任务时,由于mmdetection3d的自定义任务仍在升级中,因此目前推荐使用kitti的预设数据格式并作出对应的修改。
自定义数据集的训练有两种方式:
使用预设的kitti数据集
数据采集平台
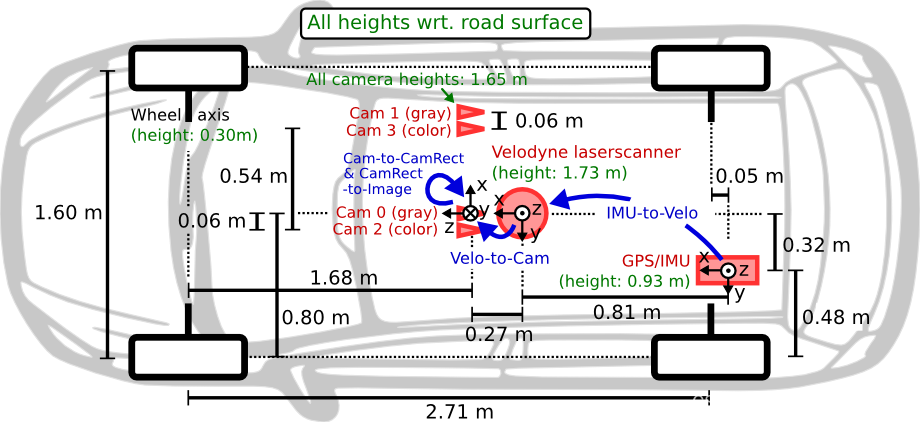
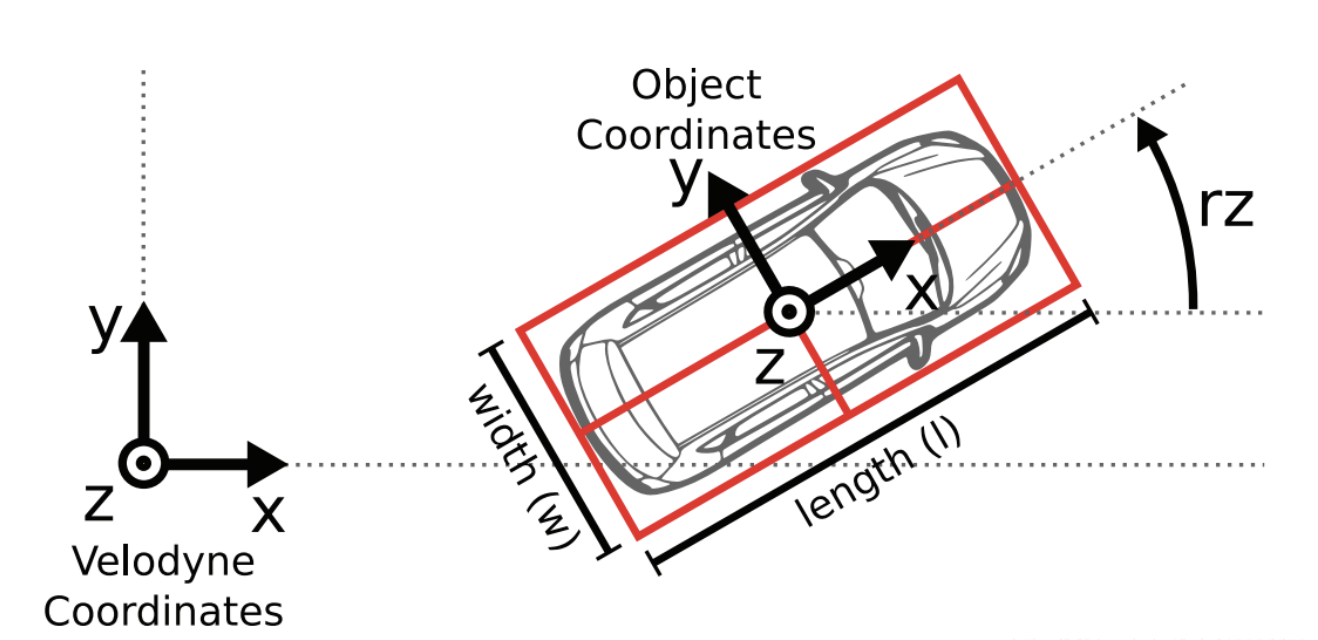
准备数据集简介
文件夹结构按如下方式组织:
mmdetection3d
├── mmdet3d
├── tools
├── configs
├── data
│ ├── kitti # 此文件夹名可自定义
│ │ ├── ImageSets
│ │ ├── testing
│ │ │ ├── calib
│ │ │ ├── image_2
│ │ │ ├── velodyne
│ │ ├── training
│ │ │ ├── calib
│ │ │ ├── image_2
│ │ │ ├── label_2
│ │ │ ├── velodyne
│ │ │ ├── planes (optional)
image文件是以8位PNG格式存储,如下所示

velodyne文件是激光雷达的测量数据,点云数据以浮点二进制文件格式存储,每行包含8个数据,每个数据由四位十六进制数表示(浮点数),每个数据通过空格隔开。一个点云数据由四个浮点数数据构成,分别表示点云的x、y、z、r(强度 or 反射值),点云的存储方式如下表所示:
8D97 9241 39B4 483D | 5839 543F 0000 0000
83C0 9241 8716 D93D | 5839 543F 0000 0000
2D32 4D42 AE47 013F | FED4 F83F 0000 0000
3789 9241 D34D 623E | 5839 543F 0000 0000
E5D0 9241 1283 803E | E17A 543F EC51 B83D
# x1 y1 z1 r1 | x2 y2 z2 r2
calib文件是相机、雷达、惯导等传感器的矫正数据
P0: 7.070493000000e+02 0.000000000000e+00 6.040814000000e+02 0.000000000000e+00 0.000000000000e+00 7.070493000000e+02 1.805066000000e+02 0.000000000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 0.000000000000e+00
P1: 7.070493000000e+02 0.000000000000e+00 6.040814000000e+02 -3.797842000000e+02 0.000000000000e+00 7.070493000000e+02 1.805066000000e+02 0.000000000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 0.000000000000e+00
P2: 7.070493000000e+02 0.000000000000e+00 6.040814000000e+02 4.575831000000e+01 0.000000000000e+00 7.070493000000e+02 1.805066000000e+02 -3.454157000000e-01 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 4.981016000000e-03
P3: 7.070493000000e+02 0.000000000000e+00 6.040814000000e+02 -3.341081000000e+02 0.000000000000e+00 7.070493000000e+02 1.805066000000e+02 2.330660000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 3.201153000000e-03
R0_rect: 9.999128000000e-01 1.009263000000e-02 -8.511932000000e-03 -1.012729000000e-02 9.999406000000e-01 -4.037671000000e-03 8.470675000000e-03 4.123522000000e-03 9.999556000000e-01
Tr_velo_to_cam: 6.927964000000e-03 -9.999722000000e-01 -2.757829000000e-03 -2.457729000000e-02 -1.162982000000e-03 2.749836000000e-03 -9.999955000000e-01 -6.127237000000e-02 9.999753000000e-01 6.931141000000e-03 -1.143899000000e-03 -3.321029000000e-01
Tr_imu_to_velo: 9.999976000000e-01 7.553071000000e-04 -2.035826000000e-03 -8.086759000000e-01 -7.854027000000e-04 9.998898000000e-01 -1.482298000000e-02 3.195559000000e-01 2.024406000000e-03 1.482454000000e-02 9.998881000000e-01 -7.997231000000e-01
calib文件中每一行代表一个参数名,冒号后面是参数矩阵,具体如下:
-
P0-P4: 矫正后的相机投影矩阵 $R^{3\times 4}$ ,其中0、1、2、3 代表相机的编号,0表示左边灰度相机,1右边灰度相机,2左边彩色相机,3右边彩色相机。
-
R0_rect: 矫正后的相机旋转矩阵 $R^{3\times 3}$,在实际计算时,需要将该3x3的矩阵扩展为4x4的矩阵,方法为在第四行和第四列添加全为0的向量。
-
Tr_velo_to_cam: 从雷达到相机的旋转平移矩阵 $R^{3\times 4}$,在实际计算时,需要将该3x4的矩阵扩展为4x4的矩阵,方法为增加第四行向量[0,0,0,1]。
-
Tr_imu_to_velo: 从惯导或GPS装置到相机的旋转平移矩阵 $R^{3\times 4}$ 。注意:将 Velodyne 坐标中的点 x 投影到左侧的彩色图像(P2)中 y,使用以下公式:
Z[u v 1]T = P2 * R0_rect * Tr_velo_to_cam * [x y z 1]T写为齐次形式,R0在右下角补1变为4x4,Tr最后一列补1变为4x4,大写Z为相机深度
若想将激光雷达坐标系中的点x投射到其他摄像头,只需替换P2矩阵即可(例如右边的彩色相机P3)。
Label 文件的文件格式为txt,内容格式为kitti格式,具体如下:
Car 0.00 0 -0.20 712.40 143.00 810.73 307.92 1.89 0.48 1.20 1.84 1.47 8.41 0.01
#type|0,1|0,1,2,3|-π ~ π(rad)|xmin|ymin|xmax|ymax|height|width|length|x|y|z|-π ~ π (rad)
#标签类型[1] 截断程度[2] 遮挡程度[3] 观测角[4] 2D标注框[5:8] 3D框的高、宽、长[9:11] 位置[12:14] 方向角[15]
# 值 名称 描述
----------------------------------------------------------------------------
1 类型 描述检测目标的类型:'Car','Van','Truck',
'Pedestrian','Person_sitting','Cyclist','Tram',
'Misc' 或 'DontCare'
1 截断程度 从 0(非截断)到 1(截断)的浮点数,其中截断指的是离开检测图像边界的检测目标
1 遮挡程度 用来表示遮挡状态的四种整数(0,1,2,3):
0 = 可见,1 = 部分遮挡
2 = 大面积遮挡,3 = 未知
1 观测角 观测目标的角度,取值范围为 [-pi..pi]
4 2D标注框 检测目标在图像中的二维标注框(以0为初始下标):包括每个检测目标的左上角和右下角的坐标
3 维度 检测目标的3D框的三维维度:高度、宽度、长度(以米为单位)
3 位置 相机坐标系下的3D框中心三维位置 x,y,z(以米为单位)
1 方向角 相机坐标系下检测目标绕着竖直轴的旋转角,取值范围为 [-pi..pi]
1 得分 仅在计算结果时使用,检测中表示置信度的浮点数,用于生成 p/r 曲线,在p/r 图中,越高的曲线表示结果越好。
Planes文件是由 AVOD 生成的道路平面信息,其在训练过程中作为一个可选项,用来提高模型的性能,以kitti/training/planes/000000.txt文件为例,内容如下。此文件不是强制文件
# Matrix
WIDTH 4
HEIGHT 1
-7.051729e-03 -9.997791e-01 -1.980151e-02 1.680367e+00
calib与image_2文件不参与训练,它们的文件名与点云文件velodyne与标注文件label一一对应仅在后处理时3d检测框投影到2d图像上发挥作用,因此calib与image_2文件可以使用fake file。
可以使用以下代码生成calib文件
import os
def generate_calib_files(input_folder, output_folder, custom_content):
# 确保输出文件夹存在
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 遍历输入文件夹中的txt文件
for filename in os.listdir(input_folder):
if filename.endswith('.txt'):
# 构建输出文件的完整路径
output_filepath = os.path.join(output_folder, filename)
# 写入新的txt文件
with open(output_filepath, 'w') as output_file:
output_file.write(custom_content.lstrip('\n'))
print(f"生成了新的calib文件:{output_filepath}")
# 输入文件夹路径
input_folder_path = 'kitti_labels'
# 输出文件夹路径
output_folder_path = 'calib'
# 自定义内容
custom_content = '''
P0: 7.070493000000e+02 0.000000000000e+00 6.040814000000e+02 0.000000000000e+00 0.000000000000e+00 7.070493000000e+02 1.805066000000e+02 0.000000000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 0.000000000000e+00
P1: 7.070493000000e+02 0.000000000000e+00 6.040814000000e+02 -3.797842000000e+02 0.000000000000e+00 7.070493000000e+02 1.805066000000e+02 0.000000000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 0.000000000000e+00
P2: 7.070493000000e+02 0.000000000000e+00 6.040814000000e+02 4.575831000000e+01 0.000000000000e+00 7.070493000000e+02 1.805066000000e+02 -3.454157000000e-01 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 4.981016000000e-03
P3: 7.070493000000e+02 0.000000000000e+00 6.040814000000e+02 -3.341081000000e+02 0.000000000000e+00 7.070493000000e+02 1.805066000000e+02 2.330660000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 3.201153000000e-03
R0_rect: 9.999128000000e-01 1.009263000000e-02 -8.511932000000e-03 -1.012729000000e-02 9.999406000000e-01 -4.037671000000e-03 8.470675000000e-03 4.123522000000e-03 9.999556000000e-01
Tr_velo_to_cam: 6.927964000000e-03 -9.999722000000e-01 -2.757829000000e-03 -2.457729000000e-02 -1.162982000000e-03 2.749836000000e-03 -9.999955000000e-01 -6.127237000000e-02 9.999753000000e-01 6.931141000000e-03 -1.143899000000e-03 -3.321029000000e-01
Tr_imu_to_velo: 9.999976000000e-01 7.553071000000e-04 -2.035826000000e-03 -8.086759000000e-01 -7.854027000000e-04 9.998898000000e-01 -1.482298000000e-02 3.195559000000e-01 2.024406000000e-03 1.482454000000e-02 9.998881000000e-01 -7.997231000000e-01
'''
# 生成calib文件
generate_calib_files(input_folder_path, output_folder_path, custom_content)
ImageSets文件夹中的文件写入了划分数据集的文件名,如下所示:
# train.txt
000000
000001
000002
000003
数据预处理方法
通过以下代码预处理数据集并生成pkl文件
python tools/create_data.py kitti --root-path ./data/kitti --out-dir ./data/kitti --extra-tag kitti
处理后的文件夹结构形式为:
kitti
├── ImageSets
│ ├── test.txt
│ ├── train.txt
│ ├── trainval.txt
│ ├── val.txt
├── testing
│ ├── calib
│ ├── image_2
│ ├── velodyne
│ ├── velodyne_reduced
├── training
│ ├── calib
│ ├── image_2
│ ├── label_2
│ ├── velodyne
│ ├── velodyne_reduced
│ ├── planes (optional)
├── kitti_gt_database
│ ├── xxxxx.bin
├── kitti_infos_train.pkl
├── kitti_infos_val.pkl
├── kitti_dbinfos_train.pkl
├── kitti_infos_test.pkl
├── kitti_infos_trainval.pkl
各个文件的意义可参考官方kitti数据集说明文档
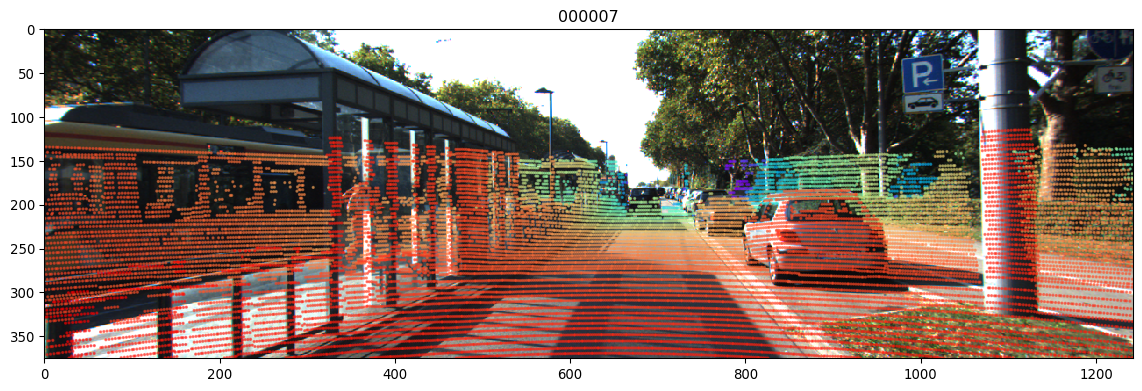
velodyne_reduced/xxxxx.bin:文件内容是将原始 velodyne 文件中的点云进行了裁剪,只保留了相机前方90°的点云数据,而舍弃了其它未标注的点云数据,如下图所示,velodyne_reduced 文件内容是图中虚线内的点云数据

kitti_gt_database/xxxxx.bin:文件内容是将原始 velodyne 文件中每个场景下的汽车、行人和自行车的点云都单独裁剪出来,包含在 3D 标注框中的点云数据,用于训练时进行数据增强。
kitti_infos_train.pkl:训练数据集,该字典包含了两个键值:metainfo 和 data_list。metainfo 包含数据集的基本信息,例如 categories, dataset 和 info_version。data_list 是由字典组成的列表,每个字典(以下简称 info)包含了单个样本的所有详细信息。
info[‘sample_idx’]:该样本在整个数据集的索引。info[‘images’]:多个相机捕获的图像信息。是一个字典,包含 5 个键值:CAM0, CAM1, CAM2, CAM3, R0_rect。info[‘images’][‘R0_rect’]:校准旋转矩阵,是一个 4x4 数组。info[‘images’][‘CAM2’]:包含 CAM2 相机传感器的信息。info[‘images’][‘CAM2’][‘img_path’]:图像的文件名。info[‘images’][‘CAM2’][‘height’]:图像的高。info[‘images’][‘CAM2’][‘width’]:图像的宽。info[‘images’][‘CAM2’][‘cam2img’]:相机到图像的变换矩阵,是一个 4x4 数组。info[‘images’][‘CAM2’][‘lidar2cam’]:激光雷达到相机的变换矩阵,是一个 4x4 数组。info[‘images’][‘CAM2’][‘lidar2img’]:激光雷达到图像的变换矩阵,是一个 4x4 数组。
info[‘lidar_points’]:是一个字典,包含了激光雷达点相关的信息。info[‘lidar_points’][‘lidar_path’]:激光雷达点云数据的文件名。info[‘lidar_points’][‘num_pts_feats’]:点的特征维度。info[‘lidar_points’][‘Tr_velo_to_cam’]:Velodyne 坐标到相机坐标的变换矩阵,是一个 4x4 数组。info[‘lidar_points’][‘Tr_imu_to_velo’]:IMU 坐标到 Velodyne 坐标的变换矩阵,是一个 4x4 数组。
info[‘instances’]:是一个字典组成的列表。每个字典包含单个实例的所有标注信息。对于其中的第 i 个实例,我们有:info[‘instances’][i][‘bbox’]:长度为 4 的列表,以 (x1, y1, x2, y2) 的顺序表示实例的 2D 边界框。info[‘instances’][i][‘bbox_3d’]:长度为 7 的列表,以 (x, y, z, l, h, w, yaw) 的顺序表示实例的 3D 边界框。info[‘instances’][i][‘bbox_label’]:是一个整数,表示实例的 2D 标签,-1 代表忽略。info[‘instances’][i][‘bbox_label_3d’]:是一个整数,表示实例的 3D 标签,-1 代表忽略。info[‘instances’][i][‘depth’]:3D 边界框投影到相关图像平面的中心点的深度。info[‘instances’][i][‘num_lidar_pts’]:3D 边界框内的激光雷达点数。info[‘instances’][i][‘center_2d’]:3D 边界框投影的 2D 中心。info[‘instances’][i][‘difficulty’]:KITTI 官方定义的困难度,包括简单、适中、困难。info[‘instances’][i][‘truncated’]:从 0(非截断)到 1(截断)的浮点数,其中截断指的是离开检测图像边界的检测目标。info[‘instances’][i][‘occluded’]:整数 (0,1,2,3) 表示目标的遮挡状态:0 = 完全可见,1 = 部分遮挡,2 = 大面积遮挡,3 = 未知。info[‘instances’][i][‘group_ids’]:用于多部分的物体。
info[‘plane’](可选):地平面信息。
基于pointpillars算法的训练
完成数据预处理后可以进行模型训练,使用以下命令:
python tools/train.py configs/pointpillars/pointpillars_hv_secfpn_8xb6-160e_kitti-3d-car.py
参考Problems using custom data sets #253,需要调整对应文件中涉及point_cloud_range这个变量的值,涉及的文件包括但不限于kitti-3d-car.py和pointpillars_hv_secfpn_8xb6-160e_kitti-3d-car.py
修改遵循两个规则:
-
point cloud rangealong z-axis(竖直轴) /voxel_size= 1 -
point cloud rangealong x,y -axis /voxel_size是16的整数倍。其中
voxel_size是基于体素网格算法中的体素网格尺寸,在pointpillars_hv_secfpn_8xb6-160e_kitti-3d-car.py中出现。
使用自定义数据集来进行训练(更新中)
自定义数据集建议在kitti的数据格式的基础上进行修改
参考资料
需要增加或修改的文件如下:
mmdetection3d
├── configs
│ ├── _base_
│ │ ├── datasets
│ │ │ ├── kitti-hid.py #文件名可自定义
├── mmdet
│ ├── configs
│ │ ├── _base_
│ │ │ ├── datasets
│ │ │ │ ├── kitti-hid.py #文件名可自定义
│ ├── datasets
│ │ ├── __init__.py
│ │ ├── hid_datasets.py #文件名可自定义
├── tools
│ ├── dataset_converters
│ │ ├── creat_gt_database.py
│ │ ├── hid_converter.py
│ │ ├── update_info_to_v2.py
│ ├── create_data.py
上述文件储存在github的mmdetection3d-hid中